Classificazione di testo con frequenze e regressione logistica
Martedì, 11 Agosto 2020 | NLP |
Il modello in oggetto, sebbene estremamente semplificato, consente una prima classificazione binaria di un testo in input a partire da un corpus di addestramento già classificato, lavorando direttamente sul dato testuale senza l'utilizzo di word embedding.
Le applicazioni sono quelle tipiche della classificazione binaria: sentiment analysis, rilevazione dello spam e ogni altro task nel quale sia necessario inquadrare uno specifico testo tra due possibili classi.
Chiaramente l'efficacia del sistema, viste le notevoli semplificazioni, è da valutarsi in base al grado di precisione che si ritiene soddisfacente per l'obiettivo prefissato.
Preprocessing e costruzione del dizionario
Uno step preliminare molto importante, sia per il corpus destinato all'addestramento del modello, sia per gli input da classificare, è quello del preprocessamento.
Questo passaggio ha l'obiettivo di sintetizzare e trasformare il dato testuale, escludendo una buona parte delle componenti non funzionali al fine della classificazione, e cercando per quanto possibile di trattare in modo unitario parole che declinano lo stesso significato - il tutto facendo leva sul singolo dato della singola parola/token, considerato che il modello attribuisce esclusivamente rilevanza alla presenza di parole all'interno del testo, ma non all'ordine.
Sebbene il preprocessamento sia articolato secondo fasi tipiche, è bene evidenziare che non vi è una strategia univoca che garantisce il miglior risultato - la scelta del processo più adeguato è infatti da contestualizzare agli obiettivi del task, alla tipologia e alla sintassi rilevabile nel corpus da trattare.
Vediamo in dettaglio alcuni dei passaggi più tipici del preprocessing:
Punteggiatura
La rimozione della punteggiatura è opportuna praticamente in tutti i casi, vista l'irrilevanza nel modello dell'ordine delle parole.
\(\fbox{il} \ \fbox{film} \ \fbox{è} \ \fbox{bello} \ \bbox[5px,border:2px solid red]{,} \ \fbox{mi} \ \fbox{è} \ \fbox{piaciuto} \ \fbox{molto} \ \bbox[5px,border:2px solid red]{!} \ \)
Entità
La rimozione di entità codificate (url, email, valori numerici, date, etc.) individuabili tramite pattern di caratteri, quando non siano ritenute utili al fine della classificazione.
\(\fbox{il} \ \fbox{film} \ \fbox{che} \ \bbox[5px,border:2px solid red]{\text{@Enrico}} \ \fbox{ha} \ \fbox{scelto} \ \fbox{su} \ \bbox[5px,border:2px solid red]{\text{https://www.filminteressanti.it}} \ \fbox{mi} \ \fbox{è} \ \fbox{piaciuto} \ \)
Stopword
Le parole utilizzate per la mera strutturazione sintattica della frase (congiunzioni, articoli, preposizioni, ausiliari, pronomi, aggettivi possessivi, etc.), con scarso apporto di significato intrinseco, vengono generalmente inquadrate come potenziali stopword da rimuovere, specie in applicazioni nel quale l'ordine delle parole non assume rilevanza.
E' comunque bene ripetere che la scelta delle stopword non è univoca, ma deve essere contestualizzata e verificata in relazione alla particolare applicazione e alla specifica tipologia del corpus - effettuando se del caso gli opportuni tuning.
Attualmente su Python è possibile fare riferimento a diverse librerie e framework per il NLP come ad esempio NLTK, Gensim, SpiCy che offrono classi e funzioni con stopword predefinite nelle varie lingue - per quanto riguarda NLTK ad esempio abbiamo una lista di stopword in Italiano accessibili da nltk.corpus.stopwords.words('italian').
\(\bbox[5px,border:2px solid red]{\text{il}} \ \fbox{film} \ \bbox[5px,border:2px solid red]{\text{che}} \ \bbox[5px,border:2px solid red]{\text{hai}} \ \fbox{scelto} \ \bbox[5px,border:2px solid red]{\text{mi}} \ \bbox[5px,border:2px solid red]{\text{è}} \ \fbox{piaciuto} \ \)
Stemming
Specialmente nell'elaborazione diretta di informazione testuale, parole con stessa radice ma desinenza diversa, determinata dal genere e dal numero per quanto riguarda nomi e aggettivi, oppure dal modo, dal tempo o dalla persona per quanto riguarda i verbi, possono essere opportunamente troncate in modo da ricondurle ad una unica radice.
Ciò permette di avere una rappresentazione più corretta dell'utilizzo di diverse parole che in pratica sono portatrici della stessa informazione.
Ovviamente ciò è possibile quando è effettivamente indentificabile una radice di caratteri coincidente - senza ricomprendere quindi forme irregolari o particolarmente articolate.
Anche in questo caso i principali framework di NLP offrono la relativà funzionalità, ad esempio per quanto riguarda la lingua italiana NLTK offre la classe nltk.stem.snowball.ItalianStemmer()
\(\ \bbox[3px,border:1px solid black]{pessim \color{red}{o} } \ \fbox{film} \ \bbox[3px,border:1px solid black]{recit\color{red}{ato}} \ \fbox{male} \ \rightarrow \ \fbox{pessim} \ \fbox{film} \ \fbox{recit} \ \fbox{male} \)
Lemmatizzazione
Dove assuma rilevanza la massima convergenza delle parole verso un lemma comune in grado di coglierne il significato, è possibile utilizzare in alternativa la lemmatizzazione, ovvero la riduzione di una forma flessa di una parola alla sua forma canonica.
Mentre lo stemming è limitato dalla esatta identificazione della radice testuale, che in forme verbali irregolari può risultare ambigua o inefficace (es: vado e andiamo), la lemmatizzazione opera perciò ad un livello di complessità superiore attraverso l'analisi pregressa di corpus e regole linguistiche, mirando a ricongiungere la parola alla forma canonica (es: furono -> essere).
A livello pratico questa complessità si traduce, specialmente per lingue diverse dall'inglese storicamente ben supportate, nella necessità di verificare se la precisione e affidabilità delle specifiche implementazioni risulta adeguata agli obiettivi dell'applicazione.
Per la lingua italiana indichiamo ad esempio:
- il package pattern sviluppato dal CLiPS che permette, tra le molteplici funzioni, anche una lemmatizzazione tramite la funzione parse;
- il framework spaCy , previo caricamento di un core module della lingua italiana, offre la lemmatizzazione come attributo lemma_ di ogni token.
\(\ \bbox[3px,border:1px solid black]{evit \color{red}{ate} } \ \bbox[3px,border:1px solid black]{sold\color{red}{i}} \ \bbox[3px,border:1px solid black]{butt\color{red}{ati}} \ \rightarrow \ \fbox{evitare} \ \fbox{soldo} \ \fbox{buttare}\)
Tabella delle frequenze
Dopo aver effettuato il preprocessing del testo del corpus di training, si procede a costruire un tabella con \(|V|\) righe, una per ogni token del corpus trattato, e 2 colonne, una per la classe 1 e per una la classe 0.
Per ogni frase del corpus, si procederà a conteggiare i token utilizzati ed incrementare in modo corrispondente il valore delle righe relative, ovviamente nella colonna in cui risulta classificata la frase.
Come esempio, immaginiamo di sviluppare un'applicazione di sentiment analysis binaria (quindi classi 1 = "ok" e 0 = "ko") e di star costruendo la tabella delle frequenze sul corpus di training.
Inseriamo la frase "Da vedere! Bello il film, bella la trama!", preprocessata come "ved bell film bell tram", e chiaramente classificata positivamente nella classe 1:
\(\begin{array}{r|rr} V & 1 & 0 \\ \hline \vdots & \vdots & \vdots \\ \text{film} & 43 & 46 \\ \text{bell} & 63 & 6 \\ \text{brutt} & 3 & 72 \\ \text{ved} & 39 & 36 \\ \text{tram} & 10 & 11 \\ \vdots & \vdots & \vdots \end{array} \ \Rightarrow \ \begin{array}{r|rr} V & 1 & 0 \\ \hline \vdots & \vdots & \vdots \\ \text{film} & \color{red}{44} & 46 \\ \text{bell} & \color{red}{65} & 6 \\ \text{brutt} & 3 & 72 \\ \text{ved} & \color{red}{40} & 36 \\ \text{tram} & \color{red}{11} & 11 \\ \vdots & \vdots & \vdots \end{array} \)
Costruita la tabella con tutte le frasi/documenti del corpus di training, otterremmo proprio una tabella con le frequenze dei vari token nelle varie classi.
Rappresentazione di un documento
Il modello ci permette di rappresentare in modo semplificato ogni documento o frase come un vettore di dimensione pari al numero delle classi, le cui componenti sono la somma delle relative frequenze dei token in tabella.
Ad esempio, supponendo di considerare definitiva la tabella sopra riportata, avremo che la frase "ved bell film bell tram" sarà rappresentata come \(x= \begin{bmatrix} 36 +6+46+6+11 \\ 40+65+44+65+11 \end{bmatrix} = \begin{bmatrix} 105 \\ 225 \end{bmatrix} \).
Più in generale \(x = \begin{bmatrix} x_0 \\ x_1 \end{bmatrix} = \begin{bmatrix} \sum_{w} Freq(w,0) \\ \sum_{w} Freq(w,1) \end{bmatrix}\) dove la somma è effettuata su tutti i \(w\) token del documento da rappresentare.
Regressione logistica
A questo punto, individuato un criterio per rappresentare in forma vettoriale i documenti del nostro training set e ogni altro input che potrà essere dato al modello, procediamo ad addestrare un modello minimale di regressione logistica , che riepiloghiamo sinteticamente.
L'obiettivo è individuare i parametri \(\pmb w=\begin{bmatrix} w_0 \\ w_1 \end{bmatrix}\) e \(b\) del modello di previsione \(\hat{y} = \sigma(\pmb w^\top \pmb x + b)\) che riescano ad approssimare meglio, per ogni frase del training set, la classe effettiva \(y\) (che dovrà essere alternativamente 0 o 1).
Ricordiamo che la funzione sigmoide \(\sigma(z)=\frac{1}{1+e^{-z}}\) restituisce ovviamente un valore compreso tra 0 e 1.
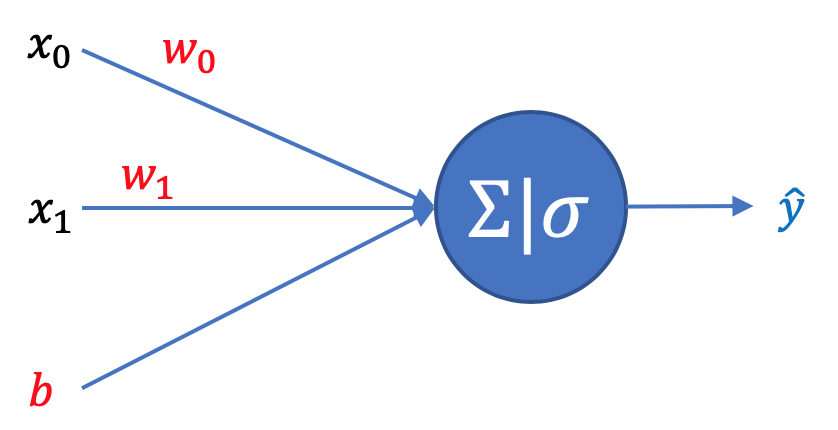
La funzione di costo che meglio rappresenta questo obiettivo è l'entropia incrociata binaria che per un singolo testo del training set è \(L=- y \log \hat {y} - (1-y)\log {(1-\hat y)}\) , difatti nel caso predizione e valore reale della classe coincidano abbiamo L=0, altrimenti L aumenta sino a diventare teoricamente infinita se il valore della predizione è completamente errato (caso \(\hat y=1-y\))
La funzione obiettivo globale da minimizzare rispetto ai parametri del modello, deve essere chiaramente estesa a tutti gli \(m\) testi del training set e normalizzata per un fattore \(\frac{1}{m}\):
\(\displaystyle J(\pmb w,b)=- \frac{1}{m} \sum_{i=1}^m [y^{(i)} \log \hat {y}^{(i)}+ (1-y^{(i)})\log {(1-\hat y^{(i)})}] \\ \ \ \ \ \ \ \ \ \ \ \ \ = -\frac{1}{m} [ \pmb y \log \pmb{\hat{y}}^\top + (1-\pmb y) \log (1-\pmb{\hat{y}})^\top]\)
dove per comodità si definiscono i vettori riga \(\pmb y\) e \(\pmb {\hat y}\) di dimensione 1 x m con tutte le classi reali e le previsioni sul set di training.
Collocando tutti gli \(m\) campioni del training set nelle colonne di una matrice \(\bf X\) di dimensione 2 x m , il calcolo del gradiente della funzione J rispetto al vettore w e allo scalare b risulta:
\( \text d\pmb w=\frac{1}{m}\bf X(\pmb{\hat y}-\pmb{y})^{\top} \) e \(\text d b=\frac{1}{m}\sum_{i=1}^{m}(\hat y^{(i)}-y^{(i)})\)
A questo punto iterando con l'algoritmo della discesa del gradiente, riusciamo ad ottenere progressivamente valori di \(\pmb w\) e \(b\) sempre migliori, riducendo ogni volta il valore della funzione obiettivo globale sino al raggiungimento di un livello di errore ritenuto soddisfacente.
Applicazione del modello e predizione
Una volta determinati i parametri \(\pmb w\) e \(b\) la predizione della classe per un testo qualsiasi è immediata.
Effettuato il preprocessing è sufficiente determinare il vettore \(\pmb x\) di rappresentazione del testo in base alla tabella delle frequenze nota, ignorando ogni token non presente in tabella, ed applicare il modello \(\hat{y} = \sigma(\pmb w^\top \pmb x + b)\).
Nel caso \(\hat y \ge 0.5\) classificheremo il testo nella classe 1, mentre nel caso \(\hat y < 0.5\) classificheremo il testo nella classe 0.
Limiti del modello
L'estema semplicità del modello, nel quale abbiamo ogni input rappresentato solo da 2 dimensioni (frequenze della classe 1 e della classe 0), e solo 3 parametri da apprendere (\(w_1 ,w_2,b\)), ci fa intuire che l'utilizzo è da destinarsi a task che si rilevano non eccessivamente complessi per i quali il modello è in grado di fornire un livello di errore accettabile.
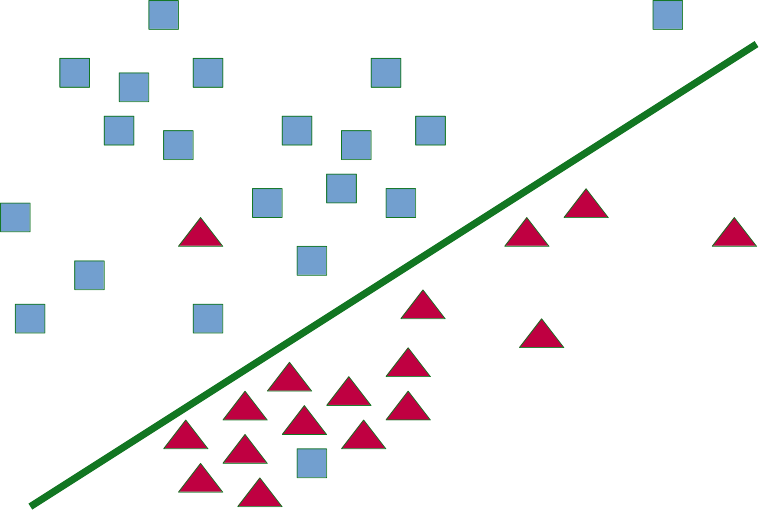
Come dalla figura seguente, la regressione logistica presenta una frontiera di decisione lineare, in grado di rappresentare bene realtà nelle quali vi è una separazione quasi-lineare tra le classi, senza pattern eccessivamente complessi che necessitano di altri modelli. Per le applicazioni indicate all'inizio, con classi generalmente correlate linearmente alla frequenza di token caratterizzanti, i risultati sono spesso accettabili.
Evoluzioni del modello
Il modello presentato può evolversi con modesti sforzi implementativi in 2 direzioni:
1) Modello di classificazione multiclasse con SoftMax: il modello consente di associare all'input 1 classe tra k arbitrarie, modificando il layer di uscita che sarà costituito da k uscite che rappresenteranno una distribuzione di probabilità sulle k possibili classi. Chiaramente il modello apprenderà un maggior numero di parametri (3 x k).
Il semplice utilizzo del SoftMax non modifica comunque la linearità delle frontiere che andranno a suddividere lo spazio dei possibili input.
2) Modello di rete neurale con aggiunta di layer nascosto: il modello prevede l'inserimento di un layer nascosto tra gli ingressi e l'uscita, con una relativa funzione di attivazione che permetta di generare una frontiera più articolata e non lineare.
Sebbene ciò permetta di rappresentare realtà più complesse c'è un rischio elevato - specie con ingressi a dimensioni ridotte come in questo caso - di overfit del modello: in pratica si rischia di ottenere un modello estremamente aderente alla realtà del training set con un errore bassissimo o nullo, ma con alti errori di previsione quando deve generalizzare su altri input .
In questo è caso è essenziale la suddivisione del corpus in training set e validation/test set, oltre all'utilizzo di meccanismi di regolarizzazione, per ottimizzare la capacità di generalizzare del modello.
