Classificazione di testo con algoritmo Naive Bayes
Domenica, 16 Agosto 2020 | NLP |
Il classificatore Naive Bayes è storicamente uno degli algoritmi più utilizzati nella classificazione di testo, dalla spam detection, alla sentiment analysis, alla classificazione per argomento in più categorie.
Sebbene oggi sia generalmente considerato superato da classificatori più articolati, sia per il fatto che le ipotesi di indipendenza sono raramente soddifatte, sia perchè non tiene in considerazione l'ordine delle parole nel testo, l'algoritmo Naive Bayes può essere utilizzato con successo in task "tipici" per i quali si registrano performance in linea con le attese.
Un punto a favore è sicuramente l'immediatezza e la facilità di uso e implementazione: il Naive Bayes si fonda esclusivamente sui teoremi del calcolo probabilistico e non prevede una fase di apprendimento iterativa con discesa del gradiente, bensì la semplice costruzione di una tabella relativa alla probabilità condizionata a partire dal training set.
Inoltre il classificatore può operare direttamente su parole/token testuali preprocessati, senza la necessità di fare riferimento a word embedding.
La probabilità condizionata e il teorema di Bayes
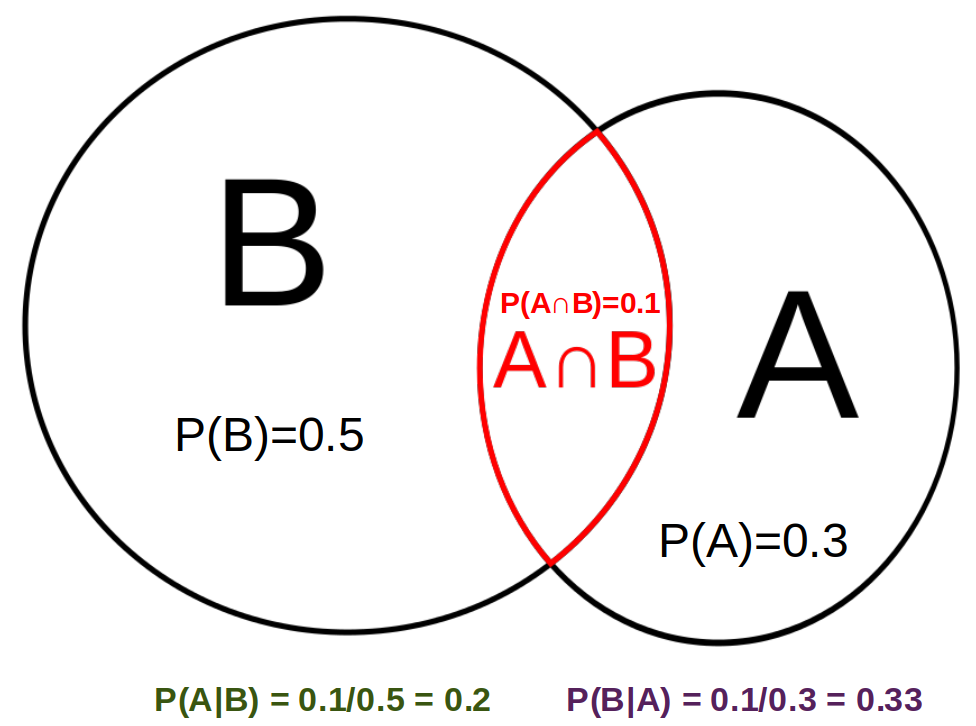
Dati due eventi A e B, si definisce probabilità condizionata \(P(A|B)\) la probabilità del verificarsi dell'evento A, condizionata al fatto che sia verificato l'evento B. Come dall'esempio in figura, è immediato verificare che questa probabilità è pari alla probabilità che i due eventi siano entrambi verificati \(P(A \cap B) \) rapportata alla probabilità che sia verificato l'evento B. Ovvero \(\displaystyle P(A|B)=\frac{P(A \cap B)}{P(B)}\)
Il Teorema di Bayes si ricava semplicemente mettendo in rapporto \(\displaystyle P(A|B)=\frac{P(A \cap B)}{P(B)}\) e \(\displaystyle P(B|A)=\frac{P(A \cap B)}{P(A)}\) , ottenendo
\(\displaystyle P(A|B)=P(B|A) \ \frac{P(A)}{P(B)}\)
Questo risultato è molto importante, in quanto ci permettere di esprimere la probabilità a posteriori P(A|B) che una determinata ipotesi A (ad esempio l'appartenza ad una determinata classe) sia verificata in presenza del verificarsi di una evidenza B (ad esempio l'occorrenza di una determinata frase da classificare), nei termini più gestibili sotto determinate assunzioni della probabilità P(B|A) che l'evidenza B sia verificata al verificarsi dell'ipotesi A, per il rapporto tra la probabilità a priori P(A) che l'ipotesi si verifichi e la probabilità marginale P(B) che l'evidenza si verifichi.
Naive Bayes
Una assunzione "naive" ma assai utile per molte applicazioni è di considerare le caratteristiche dell'evidenza B perfettamente indipendenti tra loro, senza alcuna correlazione tra gli attributi di B.
Nel caso della classificazione di testo, significa assumere che data una frase B da classificare, la presenza di una qualsiasi parola all'interno della frase è indipendente rispetto alla presenza di ogni altra parola della frase.
Questa ipotesi è chiaramente una forzatura, ma semplifica notevolmente il modello e risulta accettabile per molti task di classificazione.
Esprimendo l'evidenza B, nel nostro caso il testo da classificare, in funzione delle sue caratteristiche assunte come indipendenti, ovvero le singole parole del testo, \(B=(w_1,w_2,\cdots,w_n)\) abbiamo che \(\displaystyle P(B|A)=P(w_1,w_2,\cdots,w_n | A)=\prod_{i=1}^n P(w_i|A)\)
Possiamo quindi riscrivere il teorema come \(\displaystyle P(A|B)=\frac{P(A) \prod_{i=1}^n P(w_i|A)}{P(B)}\) , dove vedremo è possibile ricavare le varie probabilità condizionate \(P(w_i|A)\) semplicemente costruendo una tabella.
I vari \(P(A)\) delle classi sono facilmente determinati dal rapporto tra il numero di elementi del corpus (quindi frasi o testi) che rientrano nella classe A e il numero complessivo di elementi del corpus.
Per il task di classificazione non è necessario determinare esplicitamente \(P(B)\) in quanto è semplicemente un fattore di normalizzazione - dipendente solo dall'evidenza B; sarà sufficiente calcolare i soli numeratori per le varie classi e scegliere il maggiore.
A livello pratico, specie per dizionari molto estesi e/o frasi molto lunghe, i calcoli possono coinvolgere entità infinitesimali difficili da gestire con precisione, specie per calcolatori. Si preferisce quindi operare confrontando i logaritimi delle grandezze, passando quindi dal calcolo di \({P(A) \prod_{i=1}^n P(w_i|A)}\) a quello di \(\log {P(A)} + \sum_{i=1}^n \log P(w_i|A)\)
Dizionario e Tabella delle Probabilità
Partendo da un corpus già classificato di m testi in k possibili classi, l'obiettivo è quello di costruire un dizionario delle varie parole presenti nel corpus, con le relative probabilità condizionate rispetto ad ogni possibile classe, organizzate in una tabella.
Preliminarmente, in relazione agli obiettivi del task, alla tipologia del corpus e al tipo di classificazione, si procede solitamente a un preprocessing del testo attraverso varie fasi (rimozione di punteggiatura, entità e stopword, stemming o lemmatizzazione), in modo da operare già su token più semplici e significativi.
Successivamente si costruisce una tabella delle frequenze, conteggiando le frequenze dei token in ciascun testo del corpus e aggiungendole ovviamente nella colonna della classe attribuita.
Prendiamo ad esempio un'applicazione di sentiment analysis con 3 possibili classi (0=negativo 1=neutro 2=positivo) e supponiamo di dover aggiungere alla tabella delle frequenze, che abbiamo già popolato con 59 testi (20 positivi, 18 neutri e 21 negativi), una ultima frase "un film normale, nè bello, nè brutto" alla classe 1 (neutro). Dopo il preprocessamento la frase è trasformata in "film normal bell brutt" e va ad aggiornare la tabella delle frequenze:
\(\begin{array}{r|rrr} V & 2 & 1 & 0 \\ \hline \text{normal} & 12 & 43 & 15 \\ \text{film} & 33 & 36 & 30 \\ \text{bell} & 63 & 12 & 1 \\ \text{brutt} & 3 & 12 & 70 \\ \text{ved} & 39 & 36 & 30 \\ \text{tram} & 10 & 11 & 11 \end{array} \ \Rightarrow \ \begin{array}{r|rrr} V & 2 & 1 & 0 \\ \hline \text{normal} & 12 & \color{red}{44} & 15 \\ \text{film} & 33 & \color{red}{37} & 30 \\ \text{bell} & 63 & \color{red}{13} & 1 \\ \text{brutt} & 3 & \color{red}{13} & 70 \\ \text{ved} & 39 & 36 & 30 \\ \text{tram} & 10 & 11 & 11 \end{array}\)
Per passare alla tabella delle probabilità condizionate procediamo a dividere ogni elemento della tabella delle frequenze per le frequenze totali della relativa classe. Con la tabella cui sopra avremo:
\(\begin{array}{r|rrr} V & 2 & 1 & 0 \\ \hline \text{normal} & 12 & 44 & 15 \\ \text{film} & 33 & 37 & 30 \\ \text{bell} & 63 & 13 & 1 \\ \text{brutt} & 3 & 13 & 70 \\ \text{ved} & 39 & 36 & 30 \\ \text{tram} & 10 & 11 & 11 \\ \hline \color{red}{tot=471} & \color{blue}{160} & \color{blue}{154} & \color{blue}{157} \end{array} \ \ \Rightarrow \ \begin{array}{r|ccc} P(w|A) & 2 & 1 & 0 \\ \hline \text{normal} & 0,075 & 0,286 & 0,096 \\ \text{film} & 0,206 & 0,240 & 0,191 \\ \text{bell} & 0,394 & 0,084 & 0,006 \\ \text{brutt} & 0,019 & 0,084 & 0,446 \\ \text{ved} & 0,244 & 0,234 & 0,191 \\ \text{tram} & 0,063 & 0,071 & 0,070 \\ \hline & & & \end{array} \)
Infine per trovare la P(A) di una classe sarà sufficiente dividere il numero degli elementi del corpus della classe per il totale complessivo di tutti gli elementi nel corpus.
\(\begin{array}{r|ccc} A & 2 & 1 & 0 \\ \hline \color{blue}{P(A)}& \color{blue} {\frac{20}{60}=0,333}& \color{blue}{\frac{19}{60}=0,317} & \color{blue}{\frac{21}{60}=0,35} \end{array} \)
Esempio di classificazione
A partire dalle tabelle di probabilità ricavate e dalla formula derivata dal Teorema di Bayes, risulta immediato classificare una nuova frase. Prendiamo ad esempio il testo "Film interessante, trama normale ma bello da vedere", preprocessato come "film interess tram normal bell ved". Escludendo le parole non nel dizionario costruito (quindi ignoriamo "interess"), e utilizzando la più comoda tabella dei logaritmi delle probabilità riportata sotto, procediamo con i calcoli:
\(\begin{array}{r|ccc} \log P(w|A) & 2 & 1 & 0 \\ \hline \text{normal} & -2,590& -1,253& -2,348 \\ \text{film} & -1,579& -1,426& -1,655 \\ \text{bell} & -0,932& -2,472& -5,056 \\ \text{brutt} & -3,977& -2,472& -0,808 \\ \text{ved} & -1,412& -1,453& -1,655 \\ \text{tram} & -2,773& -2,639& -2,658 \\ \hline \log P(A) & -1,099 & -1,150 & -1,050 \end{array} \)
\(\log P(A|frase) = \log {P(A)} + \sum_{i=1}^n \log P(w_i|A) \ \ + c\) , dove c è il termine invariante relativo a P(B)
\(\color{green}{\log P(2|frase) = -1,099 -1,579-2,773-2,590-0,932-1,412+c=-10,385+c} \\ \log P(1|frase) = -1,150 -1,426-2,639-1,253-2,472-1,453+c=-10,393+c \\ \log P(0|frase) = -1,050 -1,655-2,658-2,348-5,056-1,655+c=-14,422+c \\ \)
Ne concludiamo quindi che il testo sarà classificato nella classe 2 (positivo) con probabilità maggiore.
Smoothing laplaciano
Dalla tabella delle probabilità condizionate, ancora più se in forma logaritmica, osserviamo che può verificarsi una situazione patologica nel caso in cui la frequenza di una parola in una determinata classe sia pari a 0, cosa che di conseguenza azzera anche \(P(w_i|A)\) e quindi \(P(A|B)\) . L'impatto dell'assenza di osservazioni della parola nella classe, a prescindere magari da un numero elevato di osservazioni delle altre parole della frase nella stessa classe, avrebbe un effetto estremamente distorsivo - specie su corpus quantitativamente limitati.
Per ovviare a ciò si procede al calcolo della tabella probabilità aggiungendo 1 ad ogni frequenza osservata, introducendo quindi un moderato effetto di "livellamento" tra le probabilità dei token in una classe, ma eliminando la distorsione connessa ad eventuali frequenze nulle.
In pratica \(\displaystyle P(w_i|A)=\frac{Freq(w_i|A)+1}{|V|+\sum_{j=1}^{|V|} Freq(w_j|A)}\)
Vediamo come si modificano le tabelle dell'esempio cui sopra introducendo lo smoothing laplaciano:
\(\begin{array}{r|ccc} \tilde P(w|A) & 2 & 1 & 0 \\ \hline \text{normal} & 0,078& 0,281& 0,098 \\ \text{film} & 0,205& 0,238 &0,190 \\ \text{bell} & 0,386& 0,088 &0,012 \\ \text{brutt} & 0,024& 0,088& 0,436 \\ \text{ved} & 0,241& 0,231& 0,190 \\ \text{tram}& 0,066 &0,075 &0,074 \\ \hline & & & \end{array} \ \ \ \Rightarrow \begin{array}{r|ccc} \log \tilde P(w|A) & 2 & 1 & 0 \\ \hline \text{normal} & -2,547& -1,269& -2,321 \\ \text{film} & -1,586 &-1,438 &-1,660 \\ \text{bell} & -0,953 & -2,436 & -4,401 \\ \text{brutt} & -3,726 & -2,436 & -0,831 \\ \text{ved} & -1,423 & -1,464 & -1,660 \\ \text{tram} & -2,714 & -2,590 & -2,609 \\ \hline & & & \end{array} \)
Come atteso, aumentano le probabilità che corrispondono a frequenze minori, a discapito di quelle relative a frequenze maggiori.
Classificazione binaria Naive Bayes
Nel caso di classificazione binaria tra due classi, è possibile semplificare ulteriormente l'algoritmo di calcolo, costruendo a partire probabilità condizionata, una tabella con un solo parametro di decisione per ogni token.
In questo caso infatti la condizione per l'attribuzione della classe positiva è semplicemente \(\frac{P(pos|frase)}{P(neg|frase)}\ge 1\) , altrimenti è ovviamente attribuita la classe negativa.
Per il teorema di Bayes, applicando l'ipotesi Naive, questa grandezza è uguale a \(\frac{P(pos) \prod_{i=1}^n P(w_i|pos)}{P(neg) \prod_{i=1}^n P(w_i|neg)}=\frac{P(pos)}{P(neg)}\prod_{i=1}^n \frac{P(w_i|pos)}{P(w_i|neg)}\).
In questo modo è possibile associare ad ogni token l'unico valore caratterizzante \(\frac{P(w_i|pos)}{P(w_i|neg)}\) che indica, se >1 un contributo della parola alla classificazione "positiva" della frase, se <1 un contributo alla classificazione negativa della parola.
Anche in questo caso, si preferisce lavorare con grandezze logaritimiche riducendo le operazioni di calcolo a sommatorie, trasformando la condizione di classificazione positiva in:
\(\displaystyle (\log P(pos)-\log P(neg))+\sum_{i=1}^n [ \log {P(w_i|pos)} - \log {P(w_i|neg)} ] \ge 0 \) , associando quindi a ogni token \(w_i \)del nostro dizionario la sola grandezza \( \log {P(w_i|pos)} - \log {P(w_i|neg)}\) , il cui segno ci indicherà se contribuisce in sommatoria alla classificazione positiva o negativa.
Rimane ovviamente da aggiungere anche il termine generale \(\log P(pos)-\log P(neg)\) che esprime il bilanciamento del training set tra il numero delle frasi positive e il numero delle frasi negative.
