Breve storia del Natural Language Processing
Lunedì, 28 Giugno 2021 | NLP |
Linguaggio e NLP
La comparsa del linguaggio verbale come forma articolata di comunicazione risale a circa 100.000 anni fa, mentre la scrittura vanta “solo” 5.000 anni di vita nei quali la capacità di trasferimento della conoscenza ha permesso uno sviluppo esponenziale della nostra civiltà. Si comprende quindi quanto sia cruciale lo studio del linguaggio, costituendo una connotazione distintiva dell’intelligenza dell’uomo rispetto a quella degli altri esseri viventi.
L’elaborazione del linguaggio naturale (comunemente indicata come NLP), si riferisce al processamento automatico del linguaggio naturale per mezzo di computer, per tutte le finalità che necessitino una comprensione del dato letterale.
Si possono individuare 3 ragioni fondamentali alla base dell’NLP1:
- comunicare in modo diretto ed efficiente con l’uomo, senza l’utilizzo di linguaggi formali;
- apprendere dalla enorme mole di conoscenza disponibile in forma di linguaggio naturale;
- comprendere in modo scientifico il linguaggio e il suo utilizzo.
In rapporto ai linguaggi formali, consueto oggetto di elaborazione, il linguaggio naturale presenta un ordine di complessità estremamente elevato, con ambiguità, ridondanze, significati impliciti e dipendenze dal contesto che ne rendono la piena comprensione un problema AI-Completo2, tanto che già Alan Turing3 individuò come test ultimo per definire l’intelligenza di una macchina proprio la capacità di comunicare attraverso il linguaggio naturale in modo indistinguibile da un umano.
Origini del NLP
Il tema più ricorrente che troviamo già agli albori del NLP negli anni ’40 è quello della Traduzione Automatica, o Machine Translation. Dopo la seconda guerra mondiale, nella quale si era notevolmente sviluppata la crittografia, lo scienziato statunitense Warren Weaver propose in un memorandum4 del 1949 una gamma di approcci più strutturati al problema della traduzione, rispetto all’usuale parola-per-parola, che avrebbero stimolato la ricerca degli anni a venire.
Le difficoltà incontrate evidenziarono il bisogno di sinergie interdisciplinari per trasporre la conoscenza tra lingue con regole non immediatamente riconducibili a una radice comune. L’opera del 1957 Syntactic Structures5 del linguista americano Noam Chomsky offrì un contributo fondamentale al problema con la grammatica generativa, insieme di regole che specificano in modo formale e ricorsivo le strutture sintattiche di un linguaggio.
Tuttavia i risultati degli anni ’60 e ’70 disattesero le aspettative riposte nel NLP e, a seguito di un report6 dell’Automatic Language Processing Advisory Committee (ALPAC) del 1966 vi fu un congelamento dei fondi USA destinati alla ricerca. Di fatto, i sistemi NLP fino agli anni ’80 erano costituiti per lo più da strutture notevolmente complesse di regole procedurali ed euristiche, con scarsa capacità di generalizzare rispetto ai problemi per i quali erano stati concepiti.
Rinascita del NLP: i modelli statistici-probabilistici
Grazie anche alla crescita esponenziale della potenza computazionale, i primi approcci di Machine Learning di tipo statistico e probabilistico7 a cavallo tra gli anni ’80 e ’90 riavviarono con forza la stagione del NLP, con un passaggio dai sistemi rule-based procedurali ed esplicitamente codificati ai sistemi corpus-based nei quali l’elaborazione è il risultato dall’addestramento del sistema su uno o più corpus di riferimento.
In particolare, per quanto riguarda la traduzione parliamo di Statistical Machine Translation (SMT), i cui parametri del modello sono inferiti statisticamente dall’analisi di due corpus, l’uno traduzione dell’altro.
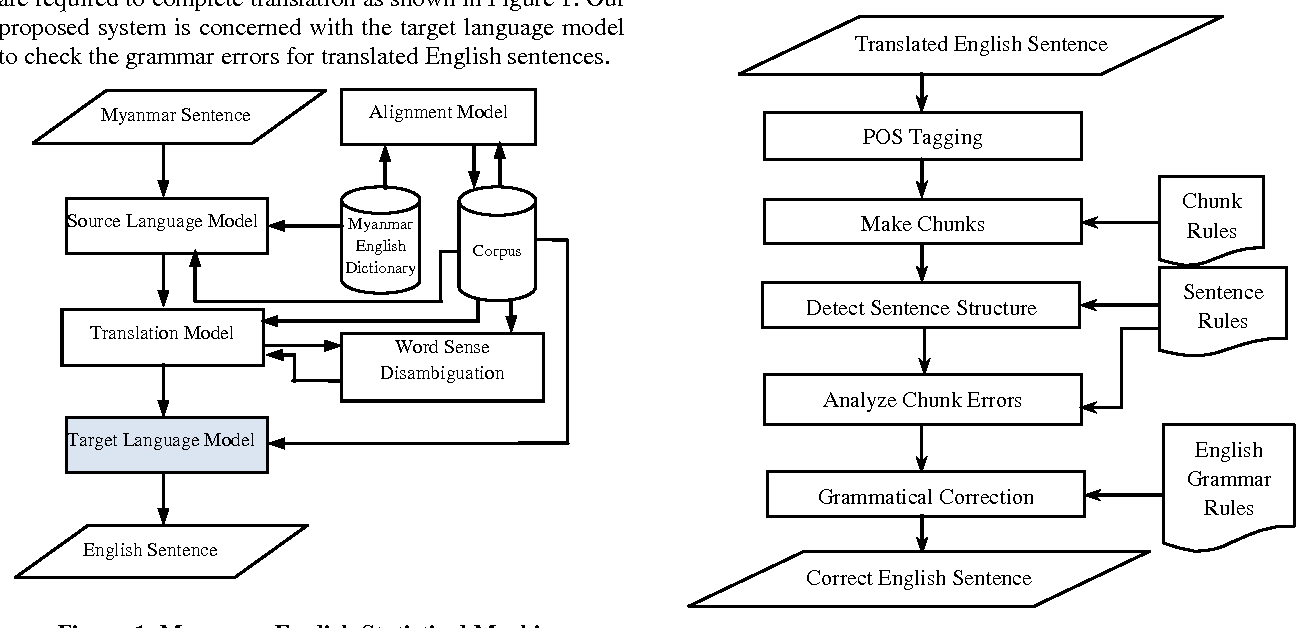
Figura 1 - Schema di SMT per la traduzione Myanmar-Inglese8
Sebbene l’approccio Statistico abbia rappresentato un enorme passo in avanti, i sistemi di MT rimanevano complessi8, basati su parole o loro sequenze (n-grammi) nella specifica lingua senza reale astrazione del significato, con sottocomponenti per gestire l’allineamento tra parole e parti di frasi nelle due lingue, e una limitata tolleranza per ambiguità, anomalie, modi di dire e parole non in vocabolario - specie tra lingue lontane strutturalmente.
La nuova era del NLP: dai sistemi complessi ai sistemi end to end
I modelli di NLP basati sull’approccio statistico-probabilistico hanno dominato la scena per oltre 20 anni, con sistemi che si sono costantemente evoluti incrementando le loro performance – due esempi su tutti Google Translate9 e Microsoft Translator che fino al 2016 erano ancora sistemi di SMT di grande complessità, con necessità di utilizzare una o più lingue “ponte” per tradurre tra lingue diverse dall’inglese.
L’anno di svolta del NLP è stato il 2013 con lo studio10 di Tomáš Mikolov nel quale viene presentato il modello Word2Vec, in grado di ricavare una rappresentazione delle parole come grandezza vettoriale.
Questi vettori, o word embedding, vengono ricavati in modo iterativo a partire dall’analisi del contesto di utilizzo delle parole nell’ambito di un corpus di addestramento, e sono in grado di cogliere nelle varie dimensioni la semantica della parola (c.d. semantica distribuzionale).
Sebbene la ricerca di una rappresentazione del testo in termini vettoriali fosse già da anni oggetto di ricerca11, anche con modelli di Latent Semantic Analysis basati su matrici di co-occorrenza e SVD12, il modello Word2Vec si è rilevato più efficace nel cogliere le relazioni tra le varie parole e computazionalmente efficiente.
La rappresentazione l’informazione testuale in forma vettoriale ha aperto la strada all’utilizzo di modelli basati su Reti Neurali (prima densamente connesse, poi convoluzionali e ricorrenti) per i vari ambiti del NLP – dalla classificazione di testo, al riconoscimento di entità, all’analisi grammaticale, e ovviamente al compito principe della Machine Translation: nel 2014 Google sviluppa il modello Sequence-to-Sequence13 (Seq2Seq) basato su Word Embedding e Reti Neurali Ricorrenti, primo vero modello di Neural Machine Translation (NMT).
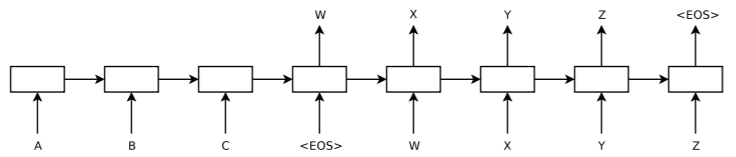
Figura 2: Seq2Seq model13
Rispetto ai sistemi SMT sviluppatisi in complessità con sottosistemi da strutturare e mantenere singolarmente, i modelli di NMT14, e più in generale i modelli di NLP basati su Reti Neurali, sono implementati come un sistema unico end-to-end, senza sottocomponenti da gestire e ottimizzare individualmente. Il tutto con performance, flessibilità e scalabilità superiori, a fronte di uno sforzo di ingegnerizzazione nettamente inferiore.
Stato dell’arte del NLP e deep learning: attention e transformer
I modelli basati esclusivamente su Reti Neurali Ricorrenti (RNN) come Seq2Seq, sebbene in grado di trattare testi di lunghezza arbitraria codificandone il significato secondo l’ordine delle parole, mostravano che la loro capacità di apprendere diminuiva in modo sensibile all’aumentare della lunghezza del testo in input, con limitata capacità di cogliere relazioni tra parole molto distanti e contesti molto articolati.
Viene così introdotto in questi modelli un meccanismo di allineamento chiamato attention15 che, una volta addestrato con il modello, riesce a focalizzare le relazioni tra le singole parti dell’input e quelle dell’output, con un sensibile miglioramento qualitativo del risultato anche su testi lunghi e articolati.
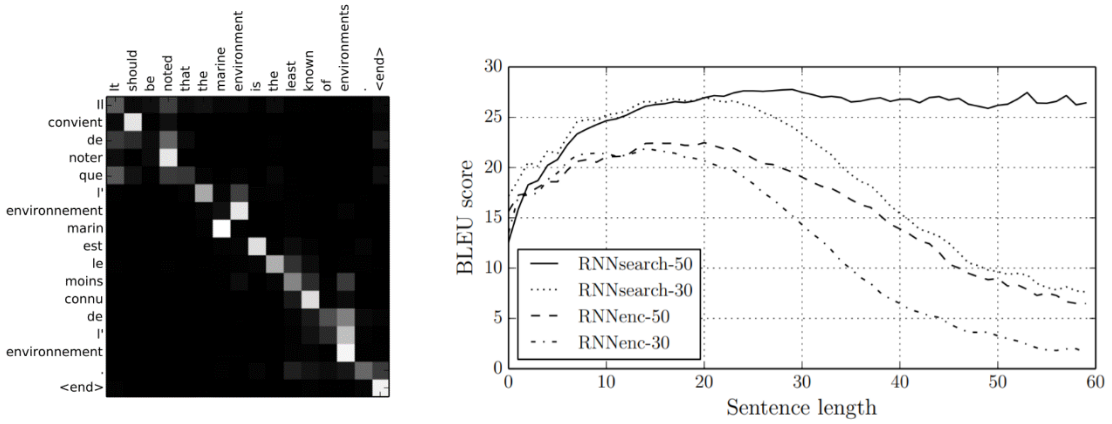 Figura 3 - Esempio di allineamento e performance RNN+attention su input di 50 parole (RNNsearch-50)15
Figura 3 - Esempio di allineamento e performance RNN+attention su input di 50 parole (RNNsearch-50)15
Pur con performance eccellenti con l’introduzione di attention e altre varianti, i modelli basati su RNN risultano ancora computazionalmente onerosi e scarsamente parallelizzabili per la natura sequenziale delle RNN, nelle quali l’input di ogni cella della rete dipende dall’output della cella adiacente. Uno dei modelli di NLP più noti di questa tipologia è ELMo16, in grado di ricavare word embedding di tipo contestuale a partire da un modello linguistico sviluppato con Reti Ricorrenti Bidirezionali, utilizzabili con successo nei problemi topici del NLP.
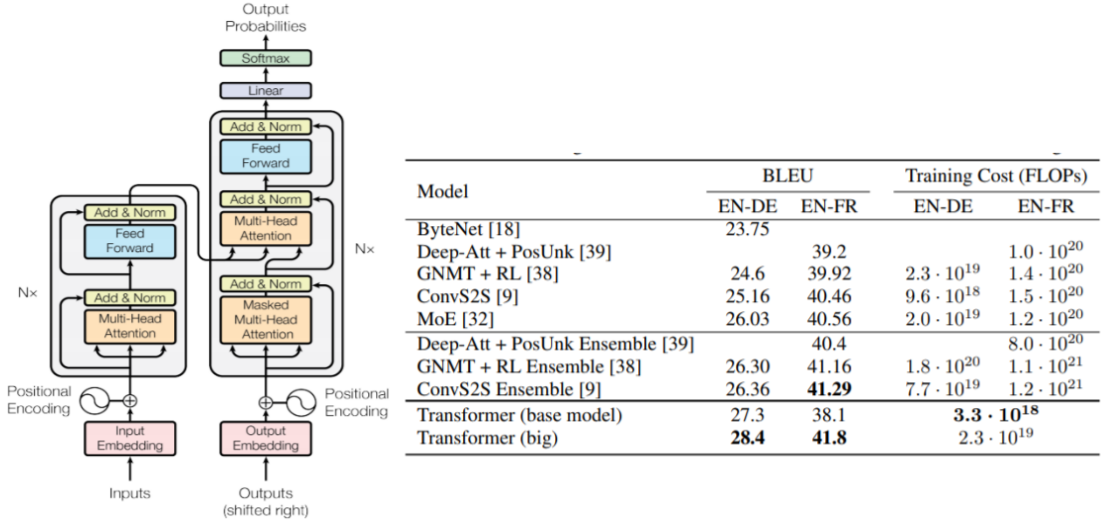
Figura 4 - Architettura del Transformer e Performance BLEU/Training Cost su Machine Translation17
Nel 2017 viene presentato il Transformer17, modello rivoluzionario che ad costituisce lo stato dell’arte alla base degli attuali sistemi di NLP: l’idea per superare i limiti delle RNN è quella di un modello basato sul solo meccanismo di attention, sia per la parte di encoder per ottenere la codifica dell’input, sia per la parte di decoder per lo sviluppo dell’output.
La struttura del Transformer senza reti sequenziali, permette uno sviluppo focalizzato sulla “verticalizzazione” in profondità dei moduli di encoding e decoding, in modo da beneficiare delle migliori performance ottenibili dall’approccio del Deep Learning con un numero sempre crescente di livelli e di parametri (già il modello nell’articolo originario prevedeva 6 layers di base per encoder e decoder). Il tutto con un costo computazionale inferiore di 1-2 ordini di grandezza rispetto ai modelli preesistenti.
Lo stato dell’arte dei sistemi NLP basati sui trasformer sono grandi modelli sviluppati in profondità e per numero di parametri, preventivamente addestrati su grandi corpus in modo non supervisionato, da calibrare con un addestramento di fine-tuning sullo specifico compito di interesse, adottando un approccio flessibile tipico del Transfer learning. Tra i modelli attualmente più utilizzati segnaliamo:
- BERT18, sviluppato e utilizzato da Google per il processamento delle query di ricerca a partire da fine 2019, con 110M-340M parametri a seconda della profondità scelta del modello.
- Il modello GPT19 (Generative Pre-Trained Transformer) sviluppato da OpenAI con 117M parametri, il successivo GPT-220 con 1,5B parametri e il più recente GPT-3 con ben 175B21 parametri.
- Il modello T522 sviluppato da Google, con 11B parameteri e un approccio unificato text-to-text che consente allo stesso modello di svolgere direttamente diversi compiti specificandoli nel testo di input.
________________________________________________
1 S. J. Russell & P. Norvig, 2021, Artificial intelligence: A modern approach (4th ed.), Hoboken: Pearson, p. 823.
2 S. C. Shapiro, 1992, Encyclopedia of Artificial Intelligence (2nd ed.), New York: John Wiley, pp. 54–57.
3 A. M. Turing, 1950, Computing Machinery and Intelligence. Mind 49: pp.433-460.
4 W. Weaver, 1949, Translation, in W. N. Locke, D. A. Booth, 1955, Machine Translation of Languages, Cambridge, Massachusetts: MIT Press. pp. 15–23.
5 N. Chomsky, 1957, Syntactic structures, 's-Gravenhage: Mouton.
6 J. R. Pierce, J. B. Carroll, et al., 1966, Language and Machines: Computers in Translation and Linguistics. ALPAC report, National Academy of Sciences, National Research Council: Washington DC
7 P. Brown, J. Cocke, S. Della Pietra, V. Della Pietra, F. Jelinek, R. Mercer, and P. Roossin, 1988, A statistical approach to language translation, in Proceedings of the 12th conference on Computational linguistics - Volume 1 (COLING '88). Association for Computational Linguistics, USA, pp.71–76
8 N. Lin, K. Soe, & N.L. Thein, 2011, Chunk-based Grammar Checker for Detection Translated English Sentences, International Journal of Computer Applications, 28, pp. 7-12.
9 F. Och,, 28.04.2006, Statistical machine translation live, Retrieved March 30, 2021, from https://ai.googleblog.com/2006/04/statistical-machine-translation-live.html
10 T. Mikolov, I. Sutskever, K. Chen, G. Corrado & J. Dean, 2013, Distributed representations of words and phrases and their compositionality, arXiv preprint arXiv:1310.4546.
11 K. Lund, C. Burgess, 1996, Producing high-dimensional semantic spaces from lexical co-occurrence, in Behavior Research Methods, Instruments, & Computers 28, pp.203–208.
12 D.L. Rohde, L.M. Gonnerman, & D.C. Plaut, 2006, An improved model of semantic similarity based on lexical co-occurrence, Communications of the ACM, 8(627-633), 116.
13 I. Sutskever, O. Vinyals, & Q.V. Le, 2014, Sequence to sequence learning with neural networks, arXiv preprint arXiv:1409.3215.
14 C. Manning, 02/02/2021, Machine Translation, Sequence-to-Sequence and Attention, in CS224n: NLP with Deep Learning, Stanford University, ultimo accesso: 02/04/2021, http://web.stanford.edu/class/cs224n/slides/cs224n-2021-lecture07-nmt.pdf , p.47
15 D.Bahdanau, K. Cho & Y. Bengio, 2014, Neural machine translation by jointly learning to align and translate, arXiv preprint arXiv:1409.0473.
16 M.E. Peters, M. Neumann, M. Iyyer, M. Gardner, C. Clark, K. Lee & L. Zettlemoyer, 2018, Deep contextualized word representations, arXiv preprint arXiv:1802.05365.
17 A.Vaswani, N.Shazeer, N.Parmar, J.Uszkoreit, L.Jones, A.Gomez, L.Kaiser & I. Polosukhin, 2017, Attention is all you need. arXiv preprint arXiv:1706.03762.
18 J. Devlin, M.W. Chang, K. Lee & K. Toutanova, 2018, Bert: Pre-training of deep bidirectional transformers for language understanding, Google AI Language, arXiv preprint arXiv:1810.04805.
19 A. Radford, K. Narasimhan, T. Salimans & I. Sutskever, 11.06.2018, Improving language understanding by generative pre-training, OpenAI, Ultimo accesso: 08.04.2021, https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
20 A. Radford, J. Wu, R. Child, D. Luan, D. Amodei & I. Sutskever, 14.02.2019, Language models are unsupervised multitask learners, OpenAI, Ultimo accesso: 08.04.2021, https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
21 T.B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, D. Amodei et al., 2020, Language models are few-shot learners, OpenAI, arXiv preprint arXiv:2005.14165.
22 C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, P.J. Liu et al., 2020, Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer, Journal of Machine Learning Research, 21, pp. 1-67.
