Operazioni di base per il NLP: preprocessing e tokenizzazione
Martedì, 21 Dicembre 2021 | NLP |
Il preprocessing del testo
Una delle attività preliminari che incontriamo in tutti i sistemi NLP, sia statistico-probabilistici che basati su reti neurali, è quella del preprocessamento del testo, applicata trasversalmente sia al corpus sul quale è svolto l'addestramento, sia agli input da sottoporre al modello addestrato.
L'obiettivo è quello di semplificare e trasformare il dato testuale a livello di singola parola o token, escludendo parte del rumore legato a componenti non funzionali agli obiettivi del sistema e cercando di trattare in modo unitario parole riconducibili allo stesso significato.
Sebbene il preprocessamento sia spesso articolato in fasi tipiche, è bene evidenziare che non vi è una strategia univoca che garantisce il miglior risultato - la scelta del processo più adeguato è da contestualizzare al modello utilizzato, agli obiettivi del compito specifico, alla tipologia e alla sintassi del stesto rilevabile nel corpus da trattare.
In generale i modelli neurali di NLP più recenti, specie se basati su embedding a livello di carattere o di subword, necessitano di un preprocessamento ridotto rispetto ai sistemi statistico-probabilistici legati a dizionari testuali. I sistemi che beneficiano maggiormente del preprocessing sono solitamente quelli di classificazione e analoghi, nei quali il risultato è una grandezza di sintesi direttamente legata alla comprensione dell’intero input.
Presentiamo di seguito alcune delle fasi che si incontrano più frequentemente nel preprocessing:
- Rimozione della punteggiatura, particolarmente utile nei task per i quali la semantica delle singole parole è preponderante rispetto a quella indotta dal flusso del testo;
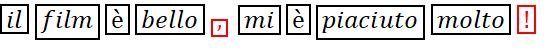
- Rimozione o sostituzione delle entità codificate, quali url, email, valori numerici, date, codici, etc. individuabili tramite pattern di caratteri, quando non portatrici di specifico significato per il compito specifico;
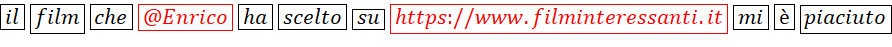
- Rimozione di stopword, parole frequenti utilizzate per la mera strutturazione sintattica della frase (congiunzioni, articoli, preposizioni, ausiliari, pronomi, aggettivi possessivi, etc.), con scarso apporto di semantica propria, specie in applicazioni nelle quali la rilevanza attribuita alle parole è da privilegiarsi rispetto a quella del flusso; si evidenzia che la scelta delle stopword non è univoca, ma deve essere contestualizzata e verificata in relazione al task e alla tipologia di testi del corpus.
Utilizzando il linguaggio di programmazione Python è possibile fare riferimento a diverse librerie e framework per il NLP come ad esempio NLTK[1], Gensim[2] e SpaCy[3] che offrono classi e funzioni con stopword predefinite nelle varie lingue - per quanto riguarda NLTK ad esempio abbiamo una lista di stopword in lingua italiana accessibili come nltk.corpus.stopwords.words('italian')[4].
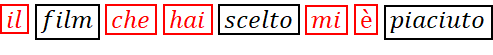
- Stemming, ovvero il troncamento delle parole alla radice, omettendo desinenze che indicano ad esempio genere, numero o alterazioni per quanto riguarda nomi e aggettivi, oppure modo, tempo o persona per quanto riguarda i verbi. Ciò assume senso se la radice risulta sufficientemente rappresentativa del significato senza rischi di ambiguità, permettendo di avere una singola rappresentazione di più parole portatrici della stessa informazione. Ovviamente essendo lo stemming un mero troncamento, non può ricondurre alla stessa radice forme irregolari o articolate.
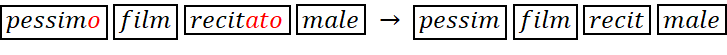
I principali framework di NLP offrono la funzionalità di stemming - per quanto riguarda la lingua italiana NLTK espone la classe nltk.stem.snowball.ItalianStemmer()[5] basata sull’algoritmo Snowball[6].
- Lemmatizzazione, ovvero la riduzione di una forma flessa di una parola alla sua forma canonica, da utilizzare in alternativa allo stemming quando si voglia ricercare la massima convergenza delle parole verso un lemma comune in grado di coglierne il significato. Mentre lo stemming si limita alla mera ricerca della radice testuale, che in forme verbali irregolari può risultare inefficace (es.: vado e andiamo), la lemmatizzazione opera ad un livello di complessità notevolmente superiore attraverso la conoscenza più profonda di corpus e regole linguistiche, dovendo ricongiungere la parola alla sua forma canonica (es: furono -> essere).
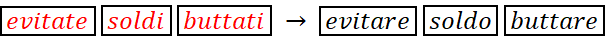
Operativamente questa complessità si traduce, specialmente per lingue diverse dall'inglese, nella necessità di verificare la rispondenza delle implementazioni della lemmatizzazione agli obiettivi del task. Per la lingua italiana segnaliamo:
- il package pattern[7] sviluppato dal CLiPS che permette, tra le molteplici funzioni, anche una lemmatizzazione tramite la funzione parse;
- il framework spaCy, che attraverso la scelta di un core module[8] della lingua italiana, offre la lemmatizzazione come componente[9] estensibile.
Tokenizzazione e costruzione del dizionario
Effettuato il preprocessing, si può procedere alla costruzione del dizionario, elenco delle entità o token presenti all’interno del corpus che andranno a costituire l’oggetto elementare di elaborazione; in un modello basato su spazi vettoriali ad ogni token corrisponderà quindi un relativo word embedding.
Solitamente, specie per i modelli pre-neurali, i token sono costituiti direttamente dalle singole parole presenti nel corpus, compresi gli elementi per rappresentare la punteggiatura (se non rimossi) e marcatori speciali di inizio fine frase: si parla in questo caso di modelli word-based.
Consideriamo per semplicità un corpus composto dalla frase:
“sono andato al mare, ho parlato al telefono e sono tornato a casa”;
in questo caso avremo un dizionario composto dai seguenti token:
“sono”, “andato”, “al”, “mare”, “ho”, “parlato”, “telefono”, “e”, “tornato”, “a”, “casa”, “,”, “.”, <START>, <END>
Chiaramente ogni frase del corpus può essere rappresentata completamente degli elementi del dizionario.
Ciò invece può non essere vero per un generico testo posto successivamente in input al sistema, che potrebbe contenere dei token non presenti nel corpus e quindi nel dizionario. Parliamo in questo caso di Out-of-Vocabulary (OOV) token.
Una delle strategie più elementari ma efficaci per gestire gli OOV è quella di costruire il dizionario utilizzando solo i token che compaiono nel corpus con una frequenza non inferiore ad una soglia k. Tutti gli altri token nel corpus saranno rappresentati nel dizionario da un token speciale <UNK>, in modo da addestrare il modello a trattare entità sconosciute.
Consideriamo per semplicità il corpus composto dalle 3 frasi con k=2:
“io mangio una mela”, “mangio al mare” e “io vado al mare”.
In questo caso ricaveremo un dizionario composto dai token:
“io”, “mangio”, “al”, “mare”, <START>, <END>, <UNK>
Il sistema NLP verrà quindi addestrato con le 3 frasi tokenizzate come
<START> io mangio <UNK> <UNK> <END>
<START> mangio al mare <END>
<START> io <UNK> al mare <END>
forzando il modello ad apprendere come trattare token sconosciuti e permettendo al sistema di accettare in input anche un testo generico. Ad esempio potremo sottoporre al modello “io mangio al parco” tokenizzandolo come <START> io mangio al <UNK> <END>.
Ovviamente questa è una strategia tanto più efficace ed efficiente quanto più è esteso il corpus, permettendo di ridimensionare dizionari che possono superare agevolmente il milione di elementi, ottenendo una buona capacità di generalizzare.
Tokenizzazione char based e subword based: SentencePiece e BPE
Con l’avvento dei modelli di NLP basati su reti neurali, e in particolare grazie alle reti convoluzionali e ricorrenti in grado di apprendere in modo sempre più efficace da pattern e sequenze di token, si sono diffuse nella pratica tokenizzazioni di più basso livello rispetto a quella word-based, sorprendentemente capaci di ottime performance e di cogliere comunque la semantica del linguaggio, pur basandosi su embedding relativi solo a parti di una parola, se non ai semplici caratteri. Vediamo più in dettaglio 2 approcci:
Tokenizzazione char-based: il testo, sia del corpus che di ogni input, è considerato a livello di carattere, separatori compresi. C’è quindi un dizionario molto compatto, nell’ordine del centinaio di token possibili per le lingue latine, ad ognuno dei quali corrisponderà un char-embedding.
Ad esempio, la frase “Ho 18 anni.” può essere tokenizzata come <START> H o 1 8 a n n i . <END>
Chiaramente in questo approccio non esistono OOV, risultando possibile rappresentare ogni possibile frase con questo dizionario.
Spesso questi char-embedding sono utilizzati in ingresso ad una CNN[10] come primo livello, per generare dinamicamente un word-embedding della parola che compongono;
Tokenizzazione subword-based: utilizzata in vari modelli allo stato dell’arte, prevede un dizionario di dimensione generalmente predeterminata, costruito partendo dalla tokenizzazione per singoli caratteri e aggiungendo in modo iterativo gruppi di più caratteri in ordine di frequenza nel corpus sino a raggiungere la dimensione prefissata.
Questo dizionario di subword sarà generalmente completo come quello char-based e conterrà prefissi, suffissi e gruppi di caratteri intermedi, ai quali saranno associati degli embedding semanticamente già portatori di significato (es: il prefisso “legg” è già ben associabile al concetto di leggere, il suffisso “ere” invece a quello di un verbo/azione).
SentencePiece[11] , uno dei tokenizer più utilizzati implementa per questo scopo l’algoritmo Byte Pair Encoding (BPE)[12]: nato per svolgere compiti di compressione, BPE si basa sulla iniziale individuazione delle parole nel corpus e delle rispettive occorrenze; ogni parola viene scomposta in caratteri (che costituiscono i token di partenza del dizionario) con l’aggiunta di un carattere di inizio parola.
Ad ogni passaggio viene individuata la coppia di token consecutivi che presenta la maggiore frequenza nel corpus e viene “promossa” a token autonomo, inserita nel dizionario e sostituita nel corpus di conseguenza, iterando sino al raggiungimento della cardinalità desiderata.
Vediamo un esempio di corpus con solo 5 parole distinte, dove tra parentesi indichiamo la frequenza della parola e in rosso il nuovo token generato dall’accorpamento della coppia di token consecutivi più frequente:
_ i o (2) _ l i b r o (2) _ l i n e a (1) _ m i o (1) _ i l (3)
_i o (2) _ l i b r o (2) _ l i n e a (1) _ m i o (1) _i l (3)
_i o (2) _l i b r o (2) _l i n e a (1) _ m i o (1) _i l (3)
_i o (2) _li b r o (2) _li n e a (1) _ m i o (1) _i l (3)
Il dizionario risultante dopo 4 iterazioni sarà quindi composto dai 12 token;
_i o _li b r n e a _ m i l
Volendo tokenizzare la frase “il mio libro” con questo dizionario, avremo:
_i l _ m i o _li b r o
[1] Natural language toolkit, ultimo accesso: 09.04.2021, https://www.nltk.org/
[2] Gensim, ultimo accesso: 09.04.2021, https://radimrehurek.com/gensim/
[3] SpaCy, ultimo accesso: 09.04.2021, https://spacy.io/
[4] NLTK: Accessing text corpora and Lexical Resources, in The NLTK book, ultimo accesso: 09.04.2021, https://www.nltk.org/book/ch02.html#stopwords_index_term
[5] Nltk.Stem package, ultimo accesso: 09.04.2021, https://www.nltk.org/api/nltk.stem.html
[6] Snowball: Italian stemming algorithm, ultimo accesso: 09.04.2021, https://snowballstem.org/algorithms/italian/stemmer.html
[7] CLiPS pattern it, ultimo accesso: 09.04.2021, https://github.com/clips/pattern/wiki/pattern-it
[8] Italian - spaCy Models Documentation, ultimo accesso: 09.04.2021, https://spacy.io/models/it
[9] Spacy - Linguistic features - Lemmatization, ultimo accesso: 09.04.2021, https://spacy.io/usage/linguistic-features#lemmatization
[10] C.D. Santos & B. Zadrozny, 2014, Learning Character-level Representations for Part-of-Speech Tagging, Proceedings of the 31st International Conference on Machine Learning, in PMLR 32(2):1818-1826
[11] T. Kudo & J. Richardson, 2018, SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing, in Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations (pp. 66-71).
[12] P. Gage, 1994, A new algorithm for data compression, in C Users Journal, 12(2), 23-38.
