GloVe: un modello efficiente per word embedding
Mercoledì, 22 Luglio 2020 | NLP |
Con il paper GloVe - Global Vectors for Word Representation (C.D.Manning, R.Socher, J.Pennington. 2014) viene presentato un modello di word embedding con i benefici sia dei metodi Latent Semantic Analysis basati su matrici statistiche globali di co-occorrenza, particolarmente efficaci nel cogliere la similarità tra parole, sia dei modelli iterativi in ottica deep-learning come Word2Vec (CBoW/Skip-Gram) basati sulla capacità di predizione della parola/contesto, efficaci nel cogliere analogie e strutture complesse.
Rapporto tra probabilità, Modello bilineare logaritmico e funzione obiettivo di GloVe
Dato un corpus testuale, dalla definizione di matrice di co-occorrenza \(X\) , l'elemento \(X_{ij}\) rappresenta il numero di volte che la parola \(j\) appare nel contesto della parola \(i\).
Di conseguenza \(\displaystyle X_i=\sum_{k \in corpus} X_{ik} \) rappresenta il numero di volte che una qualsiasi parola appare nel contesto di \(i\).
\(\displaystyle P_{ij}=(w_j|w_i)= \frac{X_{ij}}{X_i} \) è quindi la probabilità che la parola \(j\) appaia nel contesto di \(i\).
Gli autori del paper hanno osservato, come dall'esempio a seguire, che il rapporto tra probabilità di co-occorrenza può essere utilizzato proficuamente per rilevare componenti e "direttrici" di significato rilevanti:
\(\displaystyle \begin{array}{|c|c|c|c|c|} \hline & x=\text{solido} & x=\text{gas} & x=\text{acqua} & x=\text{moda} \\ \hline P(x|\text{ghiaccio}) & \color{red}{1.9 \times 10^{-4}} & \color{blue}{6.6 \times 10^{-5}} & \color{red}{3.0 \times 10^{-3}} & \color{blue}{1.7 \times 10^{-5}} \\ \hline P(x|\text{vapore}) & \color{blue}{2.2 \times 10^{-5}} & \color{red}{7.8 \times 10^{-4}} & \color{red}{2.2 \times 10^{-3}} & \color{blue}{1.8 \times 10^{-5}} \\ \hline \frac{P(x|\text{ghiaccio})}{P(x|\text{vapore})} & \color{red}{\mathbf {8.9}} & \color{blue}{\mathbf {8.5 \times 10^{-2}}} & \color{grey}{\mathbf {1.36}} & \color{grey}{\mathbf {0.96}} \\ \hline \end{array}\)
In questo esempio si rileva che "acqua" e "moda" sono due parole non discriminative in questo contesto rispetto alle parole "ghiaccio" e "vapore", avendo un rapporto tra probabilità di co-occorrenza vicino ad 1.
Invece la parola "solido", con un rapporto molto maggiore di 1, è correlabile con proprietà specifiche di "ghiaccio", mentre la parola "gas" con un rapporto molto minore di 1, è correlabile con proprietà specifiche di "vapore".
Da questo tipo di considerazione, nasce l'esigenza di strutturare un modello di embedding in grado di cogliere il significato contenuto nel rapporto di probabilità.
La soluzione individuata è quella di scegliere un modello bilineare-logaritmico tale che \(w_i \cdot \tilde w_j=\log P(i|j)\)
A questo punto si verifica che il rapporto di probabilità è riportato a una differenza di vettori \(\displaystyle w_x \cdot (\tilde w_a - \tilde w_b)=\log \frac{P(x|a)}{P(x|b)}\) che ben riflette il significato ricercato - intuitivamente, ad esempio nel caso di "moda" o "acqua", avremo degli embedding pressochè ortogonali alla direttrice degli embedding "ghiaccio"-"vapore", e quindi a prodotto scalare tendenzialmente nullo (che corrisponde ad un rapporto di probabilità unitario).
A partire da questa relazione cerchiamo di capire la struttura di una funzione di costo che ci consenta di ottimizzare i vettori.
Partendo da \(w_i^\top \tilde w_j=\log P(i|j)=\log \frac{X_{ij}}{X_i}=\log X_{ij} - \log X_i \) otteniamo che
\(w_i^\top \tilde w_j + \log X_i =\log X_{ij} \) e considerando che \(X_i \) non dipende dalla parola j può essere ricompreso in uno scalare di bias \(b_i\) da apprendere. Aggiungeremo inoltre, per salvaguardare la simmetria, un ulteriore scalare di bias \(\tilde b_j\) da apprendere relativo a \(\tilde w_j\).
Otterremo quindi una relazione \(w_i^\top \tilde w_j + b_i + \tilde b_j=\log X_{ij} \) che cercheremo di ottimizzare complessivamente per ogni i,j .
In via generale dovremmo tenere conto del caso in cui l'occorrenza \(X_{ij}\) sia nulla - evenienza molto frequente, considerando la sparsità della matrice di co-occorrenza - considerando eventualmente \(X_{ij} + 1\)
Il problema è comunque superato proprio dalla scelta della funzione obiettivo di GloVe, per la quale si utilizza il metodo dei minimi quadrati e moderata da una funzione di ponderazione \(f(X_{ij})\) nulla per \(X_{ij}=0\),
\(\displaystyle \bbox[5px,border:2px solid red] {J=\sum_{i,j=1}^V f(X_{ij})( w_i^\top \tilde w_j + b_i + \tilde b_j - \log X_{ij} )^2} \)
Nel dettaglio la \(f(X_{ij})\) sarà scelta monotona crescente con \(f(0)=0\) e relativamente contenuta per valori elevati dell'argomento , in modo da non dare eccessivo peso a co-occorrenze particolarmente frequenti.
Nel paper originale è stata utilizzata con buoni risultati la funzione
\(f(x)=\begin{cases} (x/x_\text{max})^\alpha & \text{se} \ \ x<x_\text{max} \\ 1 & \text{altrimenti} \end{cases}\) con un \(\alpha=3/4\) e un un cutoff \(x_\text{max}=100\) per non attribuire eccessivo peso a occorrenze comuni
Da Word2Vec a GloVe: denormalizzazione della funzione di costo e minimi quadrati
Vediamo come un risultato analogo può essere riscontrato partendo invece dal modello Word2Vec e introducendo la matrice di co-occorrenza per integrare e modificare le relazioni e la funzione di costo.
Riprendendo le considerazioni sugli word embedding del modello Word2Vec / Skipgram, la probabilità che una parola \(j \) compaia nel contesto della parola \(i\) viene definita come \(Q_{ij}=\frac{e^{u_j^T v_i}}{\sum_{w=1}^W e^{u_w^T v_i}}\)
In questo caso la funzione di costo globale in accordo alla cross entropy è \(\displaystyle J=-\sum_{i \in corpus}\sum_{j \in context(i)} \log Q_{ij}\)
Utilizzando convenientemente la matrice di co-occorrenza otteniamo \(J=- \sum_{i=1}^W \sum_{j=1}^W X_{ij} \log Q_{ij}\)
che può essere espresso come \(J=- \sum_{i=1}^W X_i \sum_{j=1}^W P_{ij} \log Q_{ij}=- \sum_{i=1}^W X_i H(P_i,Q_j)\) ovvero una sommatoria pesata della cross entropy tra le distribuzioni di probabilità degli word embedding e quella della matrice di co-occorrenza.
Uno dei problemi operativi legati all'utilizzo della cross entropy è il fatto che ogni distribuzione Q deve essere normalizzata sull'intero dizionario. L'approccio di GloVe è quello di utilizzare invece una funzione di costo basata invece sul modello dei minimi quadrati, senza la normalizzazione delle distribuzioni P e Q. Abbiamo quindi:
\(\displaystyle \hat{J}=\sum_{i=1}^W \sum_{j=1}^W X_i(\hat{P}_{ij}-\hat{Q}_{ij})^2\) dove \(\hat P_{ij}=\hat X_{ij} \ \ , \ \ \hat Q_{ij}=e^{u_j^\top v_i}\) sono valori non normalizzati. Per ridurre il rischio di valori esponenzialmente alti nella funzione di costo, si preferisce ottimizzare il quadrato della differenza dei logaritmi, ovvero:
\(\displaystyle \hat{J}=\sum_{i=1}^W \sum_{j=1}^W X_i(\log\hat{P}_{ij}-\log \hat{Q}_{ij})^2=\sum_{i=1}^W \sum_{j=1}^W X_i(u_j^\top v_i -\log X_{ij})^2\)
Infine, come già visto sopra, è dimostrato che si ottengono migliori risultati utilizzano un fattore di peso più articolato che il semplice \(X_i\) , utilizzando una funzione \(f(X_{ij})\) che tiene in considerazione anche la parola di contesto, e aggiungendo un parametro di bias \(b_i \) per la parola centrale ed uno \(\tilde b_j \) per la parola di contesto. Nella sua forma finale la funzione di costo, riprendendo sia i termini di bias che la funzione di ponderazione, è proprio nella forma già vista
\(\displaystyle \hat{J}=\sum_{i=1}^W \sum_{j=1}^W f(X_{ij})(u_j^\top v_i + b_i + \tilde b_j -\log X_{ij})^2\)
Considerazioni finali: efficienza nel training e risultati
I benefici del modello GloVe si ritrovano, oltre che nelle performance generalmente superiori nei task usuali (similitudini, analogie, NER) riportate nel paper ufficiale, in un training più efficiente dei parametri del modello legato ad una funzione obiettivo più agevole da ottimizzare.
La funzione è difatti condizionata da una matrice di co-occorrenza ad alta sparsità, con una computazione più snella e mirata rispetto a Word2Vec nel quale l'utilizzo di softmax prevedeva un esubero computazionale per la normalizzazione - tale da necessitare nella pratica di varianti quali il Negative Sampling per efficientare il calcolo.
__________________________________________
Riferimenti
http://nlp.stanford.edu/pubs/glove.pdf
http://web.stanford.edu/class/cs224n/readings/cs224n-2019-notes02-wordvecs2.pdf
Word2vec: modelli addestrabili per la rappresentazione distribuita delle parole
Martedì, 17 Dicembre 2019 | Deep learning | NLP |
Uno dei lavori che ha segnato il passo in ambito di Natural Language Processing è sicuramente stato il paper del 2013 Efficient Estimation of Word Representations in Vector Space (Mikolov, Corrado, Chen, Dean) , proponendo un sistema addestrabile in modo iterativo su di un corpus di documenti, in grado di apprendere il significato delle parole tramite word embedding di dimensione prefissata.
Rispetto alla matrice delle co-occorrenze, si supera il concetto del calcolo preliminare di co-occorrenze tramite matrice \(|V| \times |V|\) e la sua successiva rielaborazione tramite SVD, oneroso su dataset estesi e dizionari che possono superare ampiamente i 100k-1M di termini.
Il concetto di Word2vec si basa sull'addestramento di un modello strutturato come rete i cui parametri stessi da ricavare andranno a costituire gli word-embedding. L'output del modello verrà valutato da una opportuna funzione di costo e si aggiorneranno i parametri secondo l'algoritmo della discesa del gradiente, in modo molto simile a quanto avviene con una rete neurale tradizionale.
Word2vec viene generalmente implementato secondo 2 modelli (CBOW e Skip-Gram), a seconda che l'obiettivo della rete sia predirre una parola centrale dalle parole del suo contesto, o viceversa.
Inoltre vi sono almeno 3 varianti di criteri di addestramento/funzioni obiettivo applicabili (Softmax, Negative sampling, Hierarchical softmax), con diverse implicazioni riguardo efficienza e onere computazionale.
Iniziamo a vedere in dettaglio le varie alternative di implementazione.
Modello CBOW (Continuos Bag Of Words)
In questo modello l'obiettivo che ci si pone nell'addestramento del sistema, è quello di predirre una parola centrale a partire da una finestra nota di \(\pm m\) parole presenti nel suo contesto. Ad esempio:
\(\overset{\fbox{vado}}{x^{(c-2)}} \ \ \overset{\fbox{al}}{x^{(c-1)}} \ \ \overset{\bbox[border:2px solid red]{mare}}{y^{ } } \ \ \overset{\fbox{a}}{x^{(c+1)}} \ \ \overset{\fbox{nuotare}}{x^{(c+2)}} \)
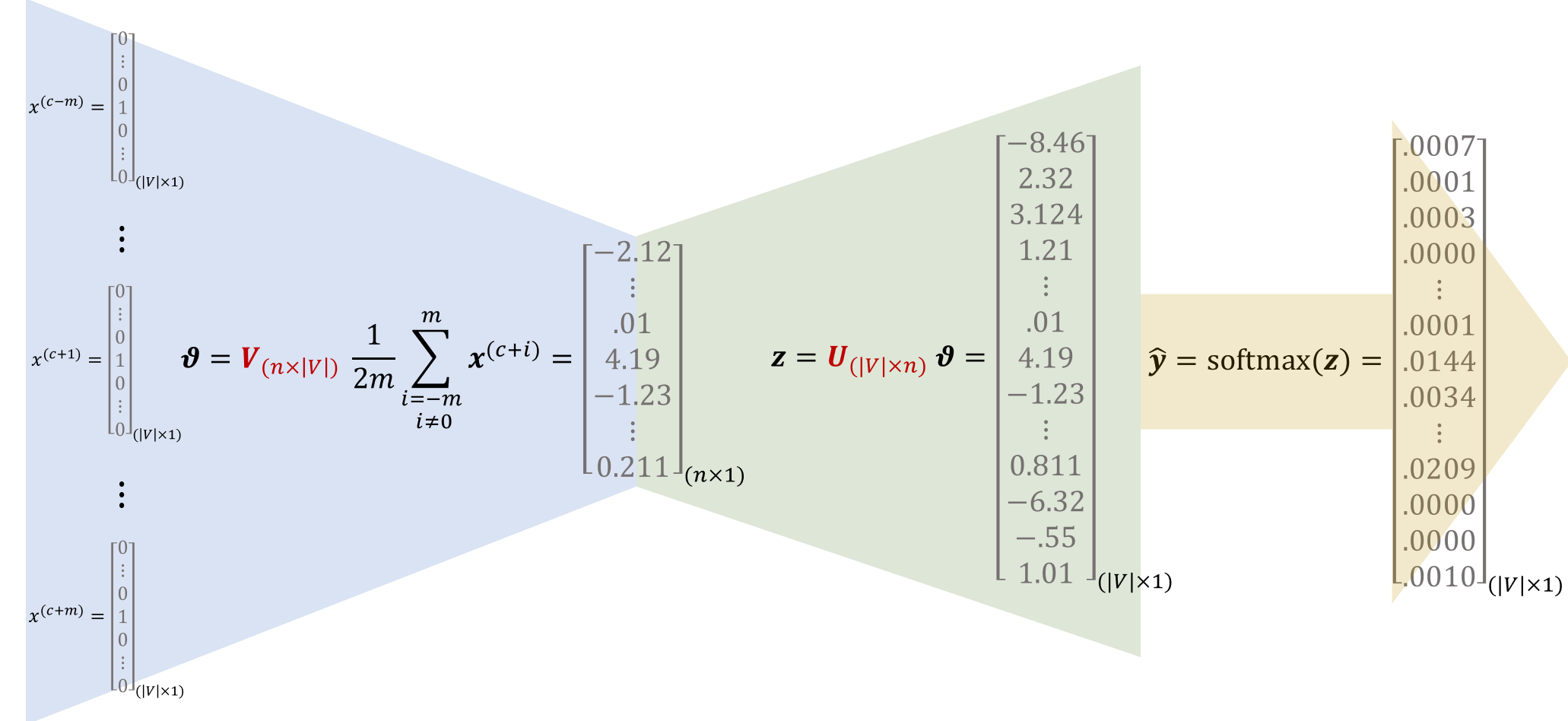
Il sistema sarà addestrato ricevendo in input le \(2m\) rappresentazioni one-hot delle parole di contesto, ciascuna di dimensione \(|V| \times 1\) , e la rappresentazione one-hot della parola centrale \(y\) effettivamente presente nella frase, che sarà confrontata con l'output del modello per aggiornare i parametri.
I parametri saranno organizzati in due matrici \(V\in\Bbb R^{n\times|V|} \ , \ U\in\Bbb R^{|V|\times n}\) , dove \(n\) è la dimensione prescelta per gli word embedding.
Vediamo che questo modello apprenderà per ogni parola due word embeddings, a seconda che la parola sia di contesto o centrale:
- la matrice \(V\) è la matrice degli embedding delle parole in input: la i-ma colonna corrisponde all'embedding della parola \(w_i \) quando questa è una parola di contesto.
- la matrice \(U\) è la matrice degli embedding delle parole in output: la j-ma riga corrisponde all'embedding della parola \(w_j \) quando questa è una parola centrale.
Come vediamo dallo schema seguente:
- il modello accetta in input le \(2m\) rappresentazioni one-hot delle parole di contesto e calcola la media dei loro word embedding \(Vx^{(i)}\) , media che costituirà una rappresentazione dell'intero contesto \(\vartheta \) ;
- Moltiplicando \(U \vartheta \) otteniamo un vettore \(z_{(|V|\times 1)}\) nel quale ogni componente sarà tanto più grande quanto più simili sono \(\vartheta \) e l'embedding della i-ma parola del dizionario rappresentata dalla i-ma riga di \(U\)
- Effettuiamo infine un \(\hat y =\text{softmax}(z)\) per ricavare una distribuzione che esprima la probabilità che la parola centrale sia quella indicata dalla relativa componente.
Per addestrare il modello dobbiamo definire una funzione obiettivo/di costo da minimizzare, in relazione alla predizione ottenuta dal modello e alla effettiva parola centrale nel contesto del corpus.
La funzione di costo più naturale da applicare per confrontare due distribuzioni di probabilità è la cross-entropy (entropia incrociata) \(J(\boldsymbol{\hat y} , \boldsymbol y)=-\sum_{i=1}^{|V|} y_i \log(\hat y_i)=-{\boldsymbol y}^\top \log {\boldsymbol {\hat y}} \) dove \(\boldsymbol{\hat y}\) è la distribuzione predetta dal modello e \(\boldsymbol y\) è la distribuzione effettiva costituita da un vettore one-hot con la c-ma componente uguale a 1, corrispondente alla parola centrale effettivamente presente nel corpus, e tutte le altre componenti uguali a 0. Detto ciò possiamo semplificare:
\(\displaystyle J(\boldsymbol{\hat y} , \boldsymbol y)=- \log(\hat y_c) = - \log P(\small w_c|w_{c-m},...,w_{c-1},w_{c+1},...,w_{c+m})=-\log{\frac{e^{u_c^\top \vartheta} }{\sum_{i=1}^{|V|}e^{u_i^\top \vartheta}}}=-u_c^\top \vartheta+\log \sum_{i=1}^{|V|}e^{u_i^\top \vartheta}\)
Grazie al calcolo dei gradienti rispetto agli word embedding \(u_i \) e \(v_j\) possiamo poi aggiornare i relativi parametri coinvolti e procedere alla ricerca del minimo con la discesa del gradiente.
Modello Skip-Gram
Questo modello si pone in un'ottica speculare al precedente, con obiettivo di massimizzare la probabilità che il sistema sia in grado di predirre le parole di contesto in una finestra di \(\pm m\) data una parola centrale. Ad esempio:
\(\displaystyle \overset{\bbox[border:2px solid red]{vado}}{y^{(c-2)}} \ \ \overset{\bbox[border:2px solid red]{al}}{y^{(c-1)}} \ \ \overset{\fbox{mare}}{x^{ } } \ \ \overset{\bbox[border:2px solid red]{a}}{y^{(c+1)}} \ \ \overset{\bbox[border:2px solid red]{nuotare}}{y^{(c+2)}} \)
Viene fatta una forte assunzione nel modello Skip-gram, ovvero che data una parola centrale le varie parole di contesto siano completamente indipendenti tra loro (i.i.d.), non condizionandosi reciprocamente.
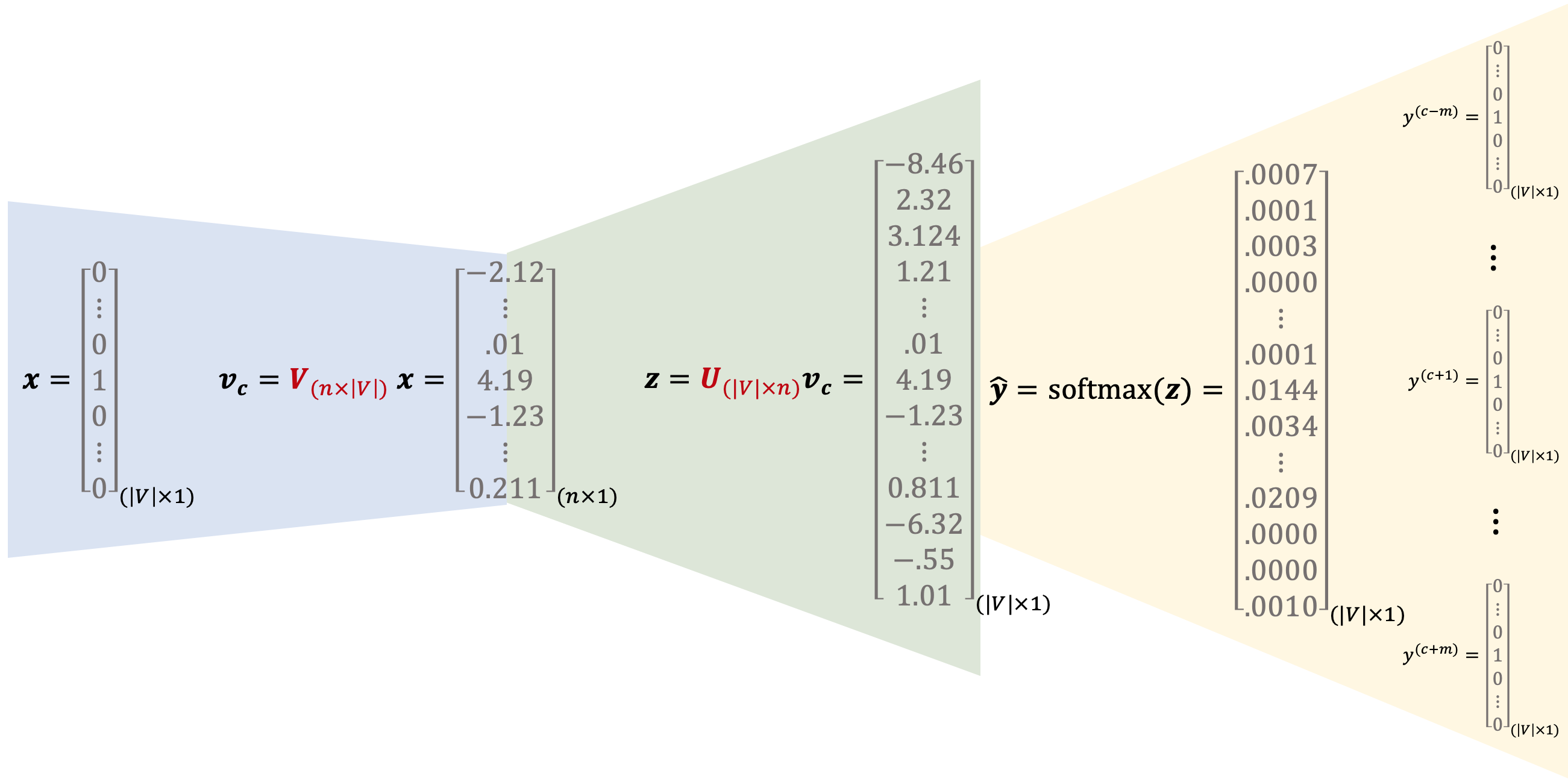
Il sistema sarà addestrato avendo in input la rappresentazione one-hot \(\boldsymbol x\) della parola centrale , di dimensione \(|V| \times 1\) , e le \(2m\) rappresentazioni one-hot delle parole di contesto \(y^{(c-m)}\cdots y^{(c+m)}\) effettivamente presenti nella frase, che saranno confrontate con la distribuzione di probabilità del contesto generata dal modello per aggiornare i parametri.
Anche in questo caso i parametri saranno organizzati in due matrici \(V\in\Bbb R^{n\times|V|} \ , \ U\in\Bbb R^{|V|\times n}\) , dove \(n\) è la dimensione desiderata degli word embedding. Specularmente al CBOW andremo ad apprendere per ogni parola due word embeddings, a seconda che la parola sia di contesto o centrale:
- la matrice \(V\) è la matrice degli embedding delle parole in input: la i-ma colonna corrisponde all'embedding della parola \(w_i \) quando questa è una parola centrale.
- la matrice \(U\) è la matrice degli embedding delle parole in output: la j-ma riga corrisponde all'embedding della parola \(w_j \) quando questa è una parola di contesto.
Come vediamo dallo schema seguente:
- il modello accetta in input la rappresentazione one-hot della parola centrale e ne calcola il corrispondente word embedding \(v_c=Vx^{(i)}\) ;
- Moltiplicando \(U v_c \) otteniamo un vettore \(z_{(|V|\times 1)}\) nel quale ogni componente sarà tanto più grande quanto più simili sono \(v_c\) e l'embedding della i-ma parola del dizionario rappresentata dalla i-ma riga di \(U\)
- Effettuiamo infine un \(\hat y =\text{softmax}(z)\) per ottenere una distribuzione che indichi la probabilità che una specifica parola di contesto sia quella espressa dalla relativa componente \(\hat y_i\)
 Per quanto riguarda la funzione obiettivo da minimizzare, tenendo conto dell'ipotesi di i.i.d. assunta, abbiamo:
Per quanto riguarda la funzione obiettivo da minimizzare, tenendo conto dell'ipotesi di i.i.d. assunta, abbiamo:
\(J =-\log P(w_{c-m},...,w_{c-1},w_{c+1},...,w_{c+m} | w_c) =\)
\(\displaystyle \ \ = -\log \prod_{j=0,j\ne m}^{2m} P(w_{c-m+j}|w_c) = -\log \prod_{j=0,j\ne m}^{2m} P(u_{c-m+j}|v_c) = \)
\(\displaystyle \ \ = -\log \prod_{j=0,j\ne m}^{2m} \frac{e^{u_{c-m+j}^\top v_c}}{\sum_{k=1}^{|V|} e^{u_k^\top v_c} } = -\sum_{j=0,j\ne m}^{2m} u_{c-m+j}^\top v_c + 2m \log \sum_{k=1}^{|V|} e^{u_k^\top v_c}\)
Volendo esprimere la funzione obiettivo in termini di cross entropy:
\(\displaystyle J = -\log \prod_{j=0,j\ne m}^{2m} P(u_{c-m+j}|v_c) = - \sum_{j=0,j\ne m}^{2m} \log P(u_{c-m+j}|v_c) = \sum_{j=0,j\ne m}^{2m} H(\hat y, y_{c-m+j}) = H(\hat y, \sum_{j=0,j\ne m}^{2m} y_{c-m+j}) \)
Grazie al calcolo dei gradienti rispetto agli word embedding \(u_i \) e \(v_j\) possiamo poi aggiornare i relativi parametri coinvolti e procedere alla ricerca del minimo con la discesa del gradiente.
Negative Sampling
Una delle problematiche dell'impostazione vista con l'utilizzo della funzione softmax è che mette in gioco per ogni calcolo tutti i \(|V|\) parametri, rendendo computazionalmente onerosa l'elaborazione nel caso di dizionari composti da milioni di parole.
La soluzione descritta di seguito, basata sul paper Distributed Representations of Words and Phrases and their Compositionality (Mikolov, Sustskever, Chen, Corrado, Dean) consiste in una approssimazione mediante il campionamento di un insieme di word embeddings estratti in accordo alla frequenza \(P_n(w)\) delle relative parole nel corpus.
Per definire la nuova funzione obiettivo, data una coppia \((w,c)\) relativa ad una parola e al suo contesto, definiamo la probabilità che tale coppia occorra effettivamente nel corpus D come \(\displaystyle P(D=1|w,c)=\sigma(u_c^\top v_w)=\frac{1}{1+e^{-u_c^\top v_w}} \) , e diversamente \(\displaystyle P(D=0|w,c)=1-\sigma(u_c^\top v_w)=\frac{1}{1+e^{u_c^\top v_w}}\)
L'obiettivo sarà quindi massimizzare la P(D=1|w,c) per le coppie effettivamente presenti nel corpus e P(D=0|w,c) per delle coppie che poniamo come non appartenenti al corpus. Stiamo di fatto ricercando i parametri \(\theta\), relativi agli embedding nelle matrici \(U,V\) , che massimizzano la probabilità:
\(\displaystyle \theta=\operatorname{argmax}\limits_{\theta} \prod_{(w,c)\in D} P(D=1|w,c,\theta)\prod_{(w,c)\in \tilde D} P(D=0|w,c,\theta)\)
La nostra funzione di costo da minimizzare sarà quindi
\(\displaystyle J=- \sum_{(w,c)\in D} \log \frac{1}{1+e^{-u_w^\top v_c}} - \sum_{(w,c)\in \tilde D} \log \frac{1}{1+e^{u_w^\top v_c}}\)
La domanda chiave è: come scegliere delle coppie (w,c) che assumiamo non appartenenti al corpus?
La soluzione adottata è quella di campionare un numero limitato e prefissato di parole K dal corpus, in accordo alla distribuzione di frequenza relativa corretta \((P_n(w))^{3/4}\) , in modo da bilanciare la probabilità di parole estremamente infrequenti.
Nel caso del modello Skip-Gram, la nostra funzione di costo relativa all'osservazione della parola di contesto c-m+j data la parola centrale c sarà:
\(\displaystyle J=- \log \sigma(u_{c-m+j}^\top v_c) - \sum_{k=1}^K \log \sigma(-\tilde u_k^\top v_c)\)
E analogamente per il modello CBOW, la funzione di costo relativa all'osservazione della parola centrale c, dato il vettore di contesto \(\displaystyle \vartheta = \frac{1}{2m} \sum_{j=0, j\ne m}^{2m} v_{c-m+j} \) avremo:
\(\displaystyle J=- \log \sigma(u_{c}^\top \vartheta) - \sum_{k=1}^K \log \sigma(-\tilde u_k^\top \vartheta)\)
Risulta evidente il minor numero di variabili, controllabile con il parametro K, coinvolte nel calcolo rispetto a quello del caso del softmax tradizionale.
Hierarchical softmax
Una diversa strategia per ridurre l'onere computazionale di un softmax tradizionale, è l'utilizzo del softmax gerarchico, che prevede la sostituzione di tutto il layer di output, matrice U compresa, con un albero binario le cui foglie sono le parole del dizionario e ogni nodo del grafo (non foglia) è associato a un word embedding che il modello apprenderà.
Vediamo lo schema dal quale ricavare un esempio concreto:
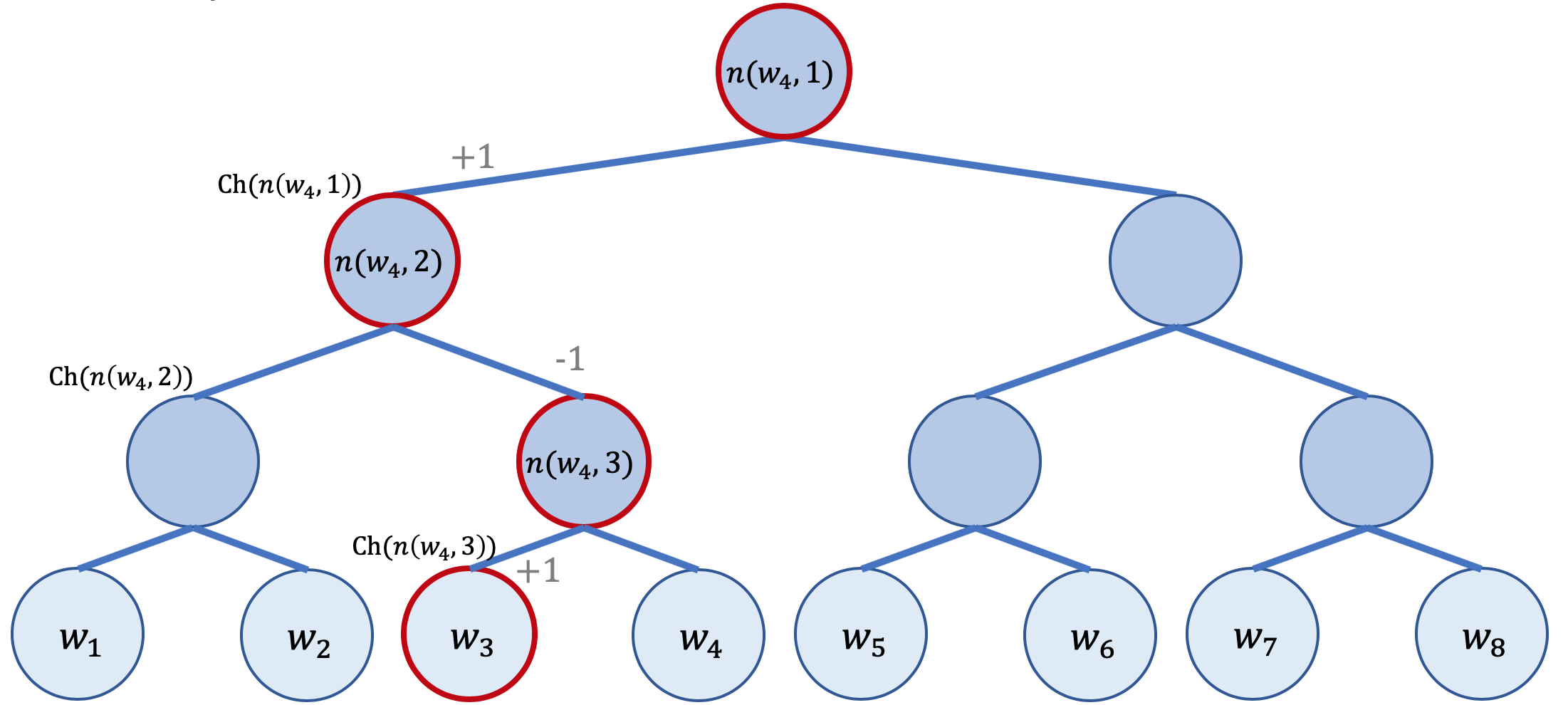
Definiamo preliminarmente:
\(L(w)\) il numero di nodi dalla radice sino alla foglia w
\(n(w,i)\) l'i-mo nodo del percorso dalla radice sino alla foglia w, con associato un vettore/embedding \(v_{n(w,i)}\)
\(\text {ch}(n)\) funzione che restituisce uno dei figli del nodo n - assumeremo per comodità sempre il nodo sinistro.
\([x]=\begin{cases} 1 \ \text{se} \ x \ \text{è vero} \\ -1 \ \text{se} \ x \ \text{è falso} \end{cases} \)
Allora possiamo calcolare la probabilità dell'occorrenza di una parola \(w\) condizionata ad una data parola \(w_i \) come:
\(\displaystyle P(w|w_i)=\prod_{j=1}^{L(w)-1} \sigma( [n(w,j+1)==\text{ch}(n(w,j))] \cdot v_{n(w,j)}^\top v_{w_i} )\)
Cerchiamo di comprendere la formula con un esempio: volendo calcolare\(P(w_3|w_i)\) come nel grafo sopra evidenziato abbiamo
\(P(w_3|w_i)=\sigma(1 \cdot v_{n(w_3,1)}^\top v_{w_i}) \cdot \sigma(-1 \cdot v_{n(w_3,2)}^\top v_{w_i}) \cdot \sigma(1 \cdot v_{n(w_3,3)}^\top v_{w_i})\)
Vediamo che il numero di embedding da ottimizzare in ogni passaggio per il modulo di softmax gerarchico è di ordine \(\log_2(|V|)\), assai inferiore a quello del softmax tradizionale. La funzione di costo da minimizzare sarà naturalmente data da \(J=- \log P(w|w_i)\) , e da questa si ricaveranno i gradienti per l'addestamento del modello.
Proprietà fondamentale del hierarchical softmax è che ad ogni nodo è assicurata la normalizzazione della probabilità, infatti a seconda del nodo figlio nel percorso (sinistro o destro) avremo una componente \(\sigma(v_{n(v,i)}^\top v_{w_i}) \) o una componente \(\sigma(-v_{n(v,i)}^\top v_{w_i}) \) , la cui somma è 1: ciò garantisce che anche \(\displaystyle \sum_{j=1}^{|V|} P(w_j|w_i) =1\) .
__________________________________________
Riferimenti
http://web.stanford.edu/class/cs224n/readings/cs224n-2019-notes01-wordvecs1.pdf
http://arxiv.org/pdf/1301.3781.pdf
http://mccormickml.com/2016/04/19/word2vec-tutorial-the-skip-gram-model/
