Pix2Pix: un modello per la trasformazione di immagini basato su GAN
Giovedì, 27 Ottobre 2022 | Deep learning | GAN |
I modelli di trasformazione image-to-image generano, a partire da una immagine di input, una differente immagine di output con l'applicazione di un determinato stile, anche complesso e con informazioni non direttamente desumibili dall'input. Alcuni esempi possono essere la generazione di una immagine a colori a partire da una immagine in bianco e nero, oppure la generazione di un panorama fotorealistico a partire da uno schema stilizzato.

Esempi di trasformazioni image-to-image1
In termini di GAN è possibile approcciare il problema come la generazione condizionata sulla base di una intera immagine - il corrispondente modello verrà quindi addestrato a partire a coppie di immagini input-output.
La logica della GAN condizionata attraverso coppie input/output può spingersi anche oltre la diretta trasformazione image-to-image.
Ad esempio è possibile condizionare la generazione di una immagine a partire dalla immagine dello stesso soggetto in una posizione diversa e da una mappa di marcatori della nuova posizione, oppure condizionare in ottica text-to-image la generazione in base ad un testo descrittivo, o infine generare un video condizionato da una immagine statica, dalla mappa dei suoi landmark, e dall'animazione dei landmark.
Pix2Pix: modello generale e addestramento
Pix2Pix1 è un modello GAN essenziale per la trasformazione image-to-image basato su coppie input/output, utilizzato come base di riferimento anche in modelli più evoluti (Pix2PixHD, GauGAN, SRGAN).
In Pix2Pix il generatore G accetterà in input una immagine x e genererà una immagine output G(x), mentre il discriminatore accetterà in input una coppia di immagini che concatenerà e che dovrà individuare come coppia reale o falsa.
L'addestramento del discriminatore D prevederà ovviamente che ogni coppia {x,G(x)} venga riconosciuta come falsa, mentre ogni coppia del dataset di training {x,y} venga riconosciuta come vera. Per quanto riguarda lo step di addestramento del generatore G invece, si cercherà di ottenere che ogni coppia {x,G(x)} sia riconosciuta come vera e capace di ingannare il discriminatore.
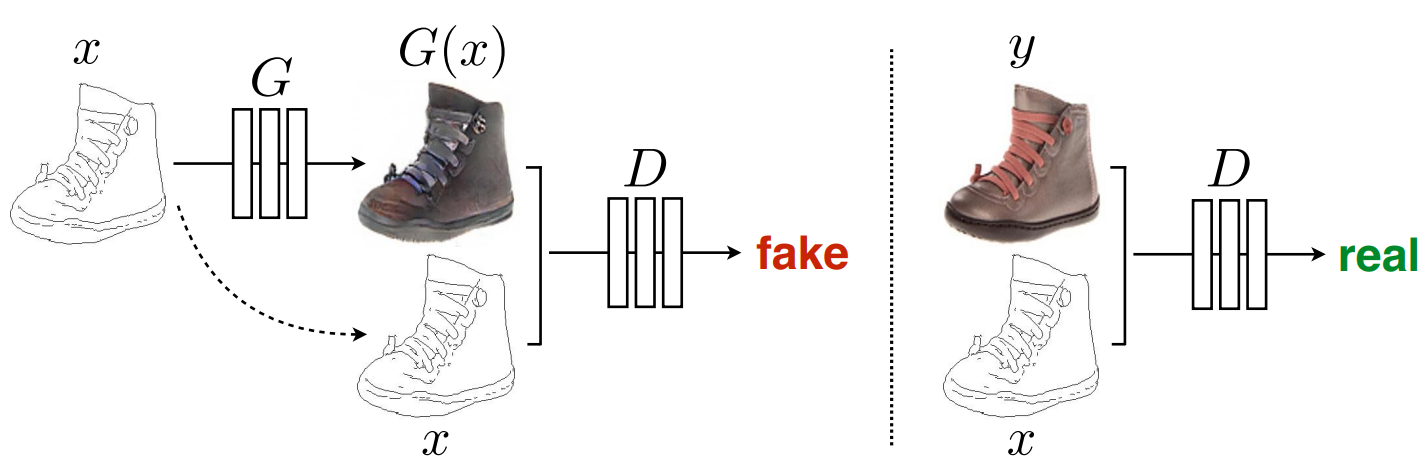
Pix2Pix: addestramento del discriminatore1
Discriminatore Pix2Pix: PatchGAN
Il discriminatore utilizzato nel modello Pix2Pix, non è un semplice discriminatore con una uscita per indicare la probabilità di verosimiglianza dell'output nel suo complesso, bensì un discriminatore PatchGAN con un output matriciale nella quale è riportata la probabilità di verosimiglianza di ogni determinata zona dell'output, in modo da favorire una rispondenza equilibrata del modello su tutte le aree dell'immagine. Chiaramente le corrispondenti label vero e falso di confronto saranno non scalari ma matrici riempite rispettivamente da 1 e 0,
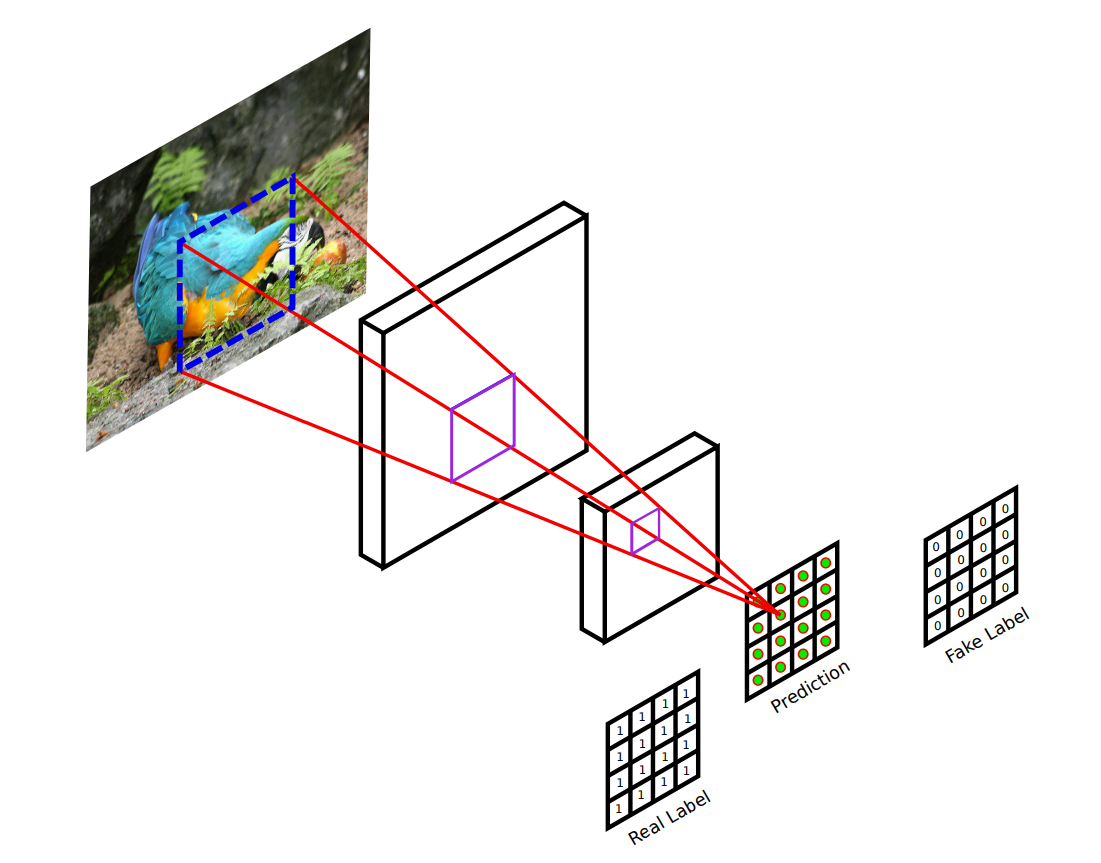
Discriminatore PatchGAN2
Generatore Pix2Pix: U-Net
L'architettura U-Net è utilizzata solitamente per compiti discriminativi di classificazione e segmentazione, dove c'è da attribuire una classe ad ogni punto dell'immagine. In questo caso la rete viene invece utilizzata come vero e proprio generatore per costruire un output verosimile.
La struttura di U-Net, in considerazione delle dimensioni analoghe di input e output, è di tipo encoder-decoder, nella quale i livelli successivi di encoding sono anche concatenati ai corrispondenti livelli di decoding attraverso delle skip-connection che agevolano sia il passaggio di informazione di dettaglio/specifica altrimenti persa nel processo di encoding, sia il flusso dei gradienti nella retropropagazione limitando il fenomeno della scomparsa del gradiente.
In alcuni blocchi del decoder possono essere inseriti dei layer di dropout che hanno la funzione, oltre che di regolarizzazione, di introdurre del rumore nella rete, (labilmente) correlato alla capacità della rete di variare l'output.
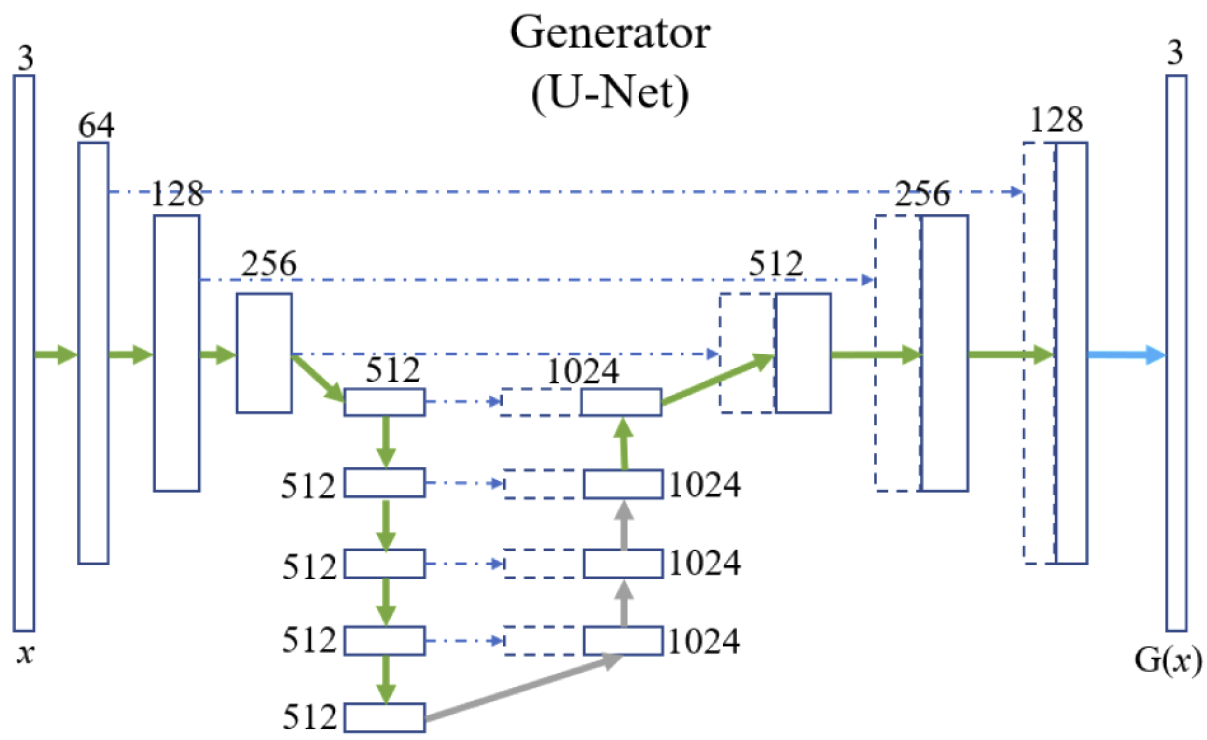
Pix2Pix U-Net Generator3
Generatore Pix2Pix: funzione di costo
La funzione di costo del modello, sulla quale ottimizzare i parametri del generatore e del discriminatore, sarà la consueta funzione BCE di costo base delle GAN condizionate \(\mathcal L(G,D)=\Bbb E_{x,y} [\log D(x,y)] + \Bbb E_{x,z}[\log(1-D(x,G(x,z))]\) che mira ad addestrare un generatore in grado di "ingannare il discriminatore", alla quale aggiungeremo un termine \(\mathcal L_{L1}=\Bbb E_{x,y,z} \lVert y-G(x,z) \rVert_1\) per incoraggiare il generatore a produrre output il più possibile aderenti a quelli del dataset reale.
Come accennato sopra, in queste formulazioni il rumore \(z\) viene inserito attraverso dei layer di dropout sia in fase di training che di test. Pertanto l'obiettivo finale del modello sarà:
\(\displaystyle \underset{G}{\min} \underset{D}{\max} \mathcal L(G,D)+\lambda \mathcal L_{L1}(G)\)
____________________
1 Isola, P., Zhu, J. Y., Zhou, T., & Efros, A. A. (2017). Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1125-1134). https://arxiv.org/abs/1611.07004
2 Demir, U., & Unal, G. (2018). Patch-based image inpainting with generative adversarial networks. arXiv preprint arXiv:1803.07422. https://arxiv.org/abs/1803.07422
3 Wang, Chenxing & Fanzhou, Wang & Guan, Qingze. (2021). Single-shot fringe projection profilometry based on Deep Learning and Computer Graphics. Optics Express. 29. 10.1364/OE.418430. https://arxiv.org/abs/2101.00814
