
GPT-5: uno step verso un'AI più completa
Giovedì, 7 Agosto 2025. OpenAI ha reso disponibile GPT-5, evoluzione e integrazione tra i modelli GPT-Series e o-Series. È progettato per gestire compiti complessi mediante un’architettura modulare costituita da due componenti principali: uno ottimizzato per risposte rapide (fast), e un modulo dedicato al ragionamento elaborato (thinking). Un router in tempo reale seleziona quale modulo attivare in funzione della complessità del prompt, del comportamento dell’utente e della correttezza delle risposte. Questo router si adatta dinamicamente, apprende da dati sulle preferenze e migliora decisio...

OpenAI rilascia i modelli GPT-OSS: disponibili due LLM open-weight da 20B e 120B parametri
Mercoledì, 6 Agosto 2025. OpenAI ha annunciato ( https://openai.com/it-IT/index/introducing-gpt-oss/ ) la disponibilità di due nuovi modelli linguistici di grandi dimensioni (LLM) denominati GPT-OSS, resi pubblici con pesi open-weight e licenza Apache 2.0. Si tratta dei primi modelli di questo tipo pubblicati da OpenAI dall’epoca di GPT-2. I modelli rilasciati sono: gpt-oss-120b – un modello con 120 miliardi di parametri gpt-oss-20b – un modello con 20 miliardi di parametri Entrambi sono disponibili per il download e l'esecuzione locale, con piena compatibilit&...

Microsoft presenta Majorana 1: il primo processore quantistico al mondo basato su qubit topologici
Venerdì, 21 Febbraio 2025. Microsoft ha annunciato Majorana 1, un Quantum Processing Unit (QPU) che rappresenta un importante passo avanti nel percorso verso il calcolo quantistico pratico. La particolarità di questo processore risiede nell’uso di qubit topologici, una tecnologia che garantisce maggiore stabilità e riduce gli errori, grazie a un’architettura intrinsecamente protetta. Majorana 1 è progettato per scalare fino a un milione di qubit su un singolo chip, aprendo nuove prospettive per lo sviluppo di computer quantistici in grado di affrontare problemi complessi oggi irrisolvibi...
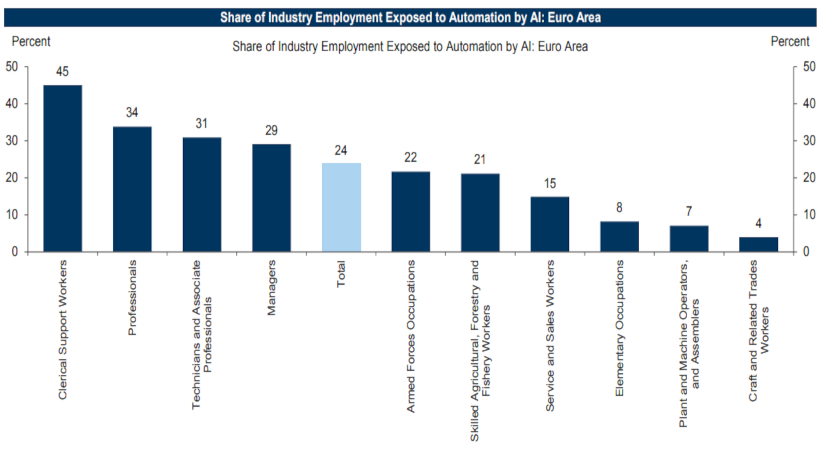
L'IA generativa rivoluziona la crescita economica globale e il mercato del lavoro
Giovedì, 30 Marzo 2023. Un recente studio di Goldman Sachs, "The Potentially Large Effects of Artificial Intelligence on Economic Growth" (Briggs, Kodnani et al.), esamina gli effetti potenzialmente significativi dell'intelligenza artificiale (IA) generativa sulla crescita economica. L'IA generativa, caratterizzata dall'uso generalizzato, dalla capacità di generare contenuti simili a quelli umani e dalle interfacce intuitive, potrebbe cambiare radicalmente il mercato del lavoro e aumentare la produttività a livello globale. Le tecnologie IA generative, come ChatGPT, DALL-E ...
Plug-in per ChatGPT: nuove capacità e accesso real time al web
Mercoledì, 29 Marzo 2023. OpenAI ha lanciato il supporto ai plug-in per ChatGPT, consentendo l'ampliamento delle capacità del chatbot e permettendogli, per la prima volta, di accedere a dati in tempo reale dal web. Fino ad ora, ChatGPT era limitato dall'impossibilità di attingere a informazioni al di fuori del dataset di addestramento, fermo a più di un anno fa. OpenAI afferma che i plug-in permetteranno al bot di interagire con siti web specifici, trasformando potenzialmente il sistema in un'interfaccia per vari servizi. In un video dimostrativo, un utente utilizza ChatGPT per tr...

La rivoluzione AI e la corsa dei colossi della tecnologia
Martedì, 28 Marzo 2023. In una call su Microsoft Teams, Jared Spataro, responsabile del software di produttività di Microsoft, dimostra come l'intelligenza artificiale (AI) riesca ad elaborare un riassunto accurato della conversazione in corso, praticamente in tempo reale. Microsoft sta implementando l'intelligenza artificiale in quasi tutti i suoi prodotti e in particolare nella suite Microsoft 365 attraverso Copilot, appoggiandosi su ChatGPT. Alphabet, la casa madre di Google, sta seguendo la stessa strada con prodotti come Gmail e Sheets. Negli ultimi mesi, anche gli altri giganti della tecnologi...
Fondamenti del Business Process Management
Mercoledì, 9 Agosto 2023 | BPM |
Nei paragrafi che seguono si vanno a introdurre sinteticamente i fondamenti della gestione per processi, modello che negli ultimi decenni ha proposto una rilettura della struttura e della dinamica dell'organizzazione imperniata sulla creazione del valore, attraverso la centralità del cliente e il soddisfacimento dei suoi bisogni. I modelli statici "tradizionali" con una gestione verticale e compartimentata delle attività in unità organizzative, siano divisioni o semplici uffici, rischiano difatti di perdere di vista il concetto di output per il cliente e spesso non sono in grado di adattarsi ai suoi bisogni sempre più variegati e mutevoli.
Ecco quindi emergere il concetto dinamico di processo, inteso come insieme di attività end-to-end che attraversano trasversalmente l’organizzazione per creare un output al quale il cliente attribuisce valore. In questa ottica il Business Process Management coinvolge l'intera organizzazione in un approccio sistematico e strutturato per analizzare, gestire, controllare e migliorare nel tempo l'insieme dei processi aziendali, integrando l'orientamento ai processi con logiche di continuous improvement.
A supporto dell’adozione del BPM, si introducono vari framework per la classificazione dei processi, come i l'APQC's PCF e SCOR, che possono essere utilizzati per identificare i processi e agevolarne la standardizzazione, beneficiando di know-how e best practice di settore. Si esaminerà anche come l’adozione del BPM possa avvenire per gradi e con diversi obiettivi a seconda dello stadio di maturità dell’organizzazione.
Saranno quindi analizzati i diversi principi da seguire per implementare efficacemente la gestione per processi:
- culturali, per riorientare la cultura aziendale, attraverso la pervasività e la logica cliente-fornitore, dalla visione statica delle unità organizzative a quella dinamica interfunzionale di attività orientate alla soddisfazione del cliente;
- organizzativi, per intervenire sulla struttura e sul funzionamento dell’organizzazione, attraverso la process ownership e il job redesign;
- gestionali, per agevolare l’integrazione dei flussi di attività e di informazioni dei processi, attraverso la documentazione (per la quale presenteremo in dettaglio lo standard BPMN), la misurazione con kpi per valutare efficienza ed efficacia, l’ottimizzazione delle attività e dei controlli;
Vedremo infine come le tecnologie digitali operino in simbiosi con il BPM, sia attraverso suite BPMS per la gestione dei processi a 360°, dalla modellazione all’esecuzione e al controllo, sia attraverso Enterprise Systems (ERP, CRM, SCM) che implementano le attività operative in ottica di processo.

Indice
1. Le dimensioni dell’organizzazione aziendale e l’orientamento al cliente: i processi aziendali
2. Evoluzione dei processi aziendali: dalla divisione del lavoro al BPM
3. Tipologia, identificazione e classificazione dei processi aziendali
4. Rappresentazione CRASO, gerarchia e livelli di analisi dei processi
5. Implementazione del BPM: fasi, maturità, fattori critici di successo e principi
6. Principi culturali: pervasività e logica cliente/fornitore
7. Principi organizzativi: process ownership e job redesign
8. Principi gestionali: la documentazione. Modellazione dei processi con BPMN
9. Principi gestionali: la misurazione
10. Principi gestionali: ottimizzazione dei flussi, controlli e bilanciamento push/pull
Pix2Pix: un modello per la trasformazione di immagini basato su GAN
Giovedì, 27 Ottobre 2022 | Deep learning | GAN |
I modelli di trasformazione image-to-image generano, a partire da una immagine di input, una differente immagine di output con l'applicazione di un determinato stile, anche complesso e con informazioni non direttamente desumibili dall'input. Alcuni esempi possono essere la generazione di una immagine a colori a partire da una immagine in bianco e nero, oppure la generazione di un panorama fotorealistico a partire da uno schema stilizzato.

Esempi di trasformazioni image-to-image1
In termini di GAN è possibile approcciare il problema come la generazione condizionata sulla base di una intera immagine - il corrispondente modello verrà quindi addestrato a partire a coppie di immagini input-output.
La logica della GAN condizionata attraverso coppie input/output può spingersi anche oltre la diretta trasformazione image-to-image.
Ad esempio è possibile condizionare la generazione di una immagine a partire dalla immagine dello stesso soggetto in una posizione diversa e da una mappa di marcatori della nuova posizione, oppure condizionare in ottica text-to-image la generazione in base ad un testo descrittivo, o infine generare un video condizionato da una immagine statica, dalla mappa dei suoi landmark, e dall'animazione dei landmark.
Pix2Pix: modello generale e addestramento
Pix2Pix1 è un modello GAN essenziale per la trasformazione image-to-image basato su coppie input/output, utilizzato come base di riferimento anche in modelli più evoluti (Pix2PixHD, GauGAN, SRGAN).
In Pix2Pix il generatore G accetterà in input una immagine x e genererà una immagine output G(x), mentre il discriminatore accetterà in input una coppia di immagini che concatenerà e che dovrà individuare come coppia reale o falsa.
L'addestramento del discriminatore D prevederà ovviamente che ogni coppia {x,G(x)} venga riconosciuta come falsa, mentre ogni coppia del dataset di training {x,y} venga riconosciuta come vera. Per quanto riguarda lo step di addestramento del generatore G invece, si cercherà di ottenere che ogni coppia {x,G(x)} sia riconosciuta come vera e capace di ingannare il discriminatore.
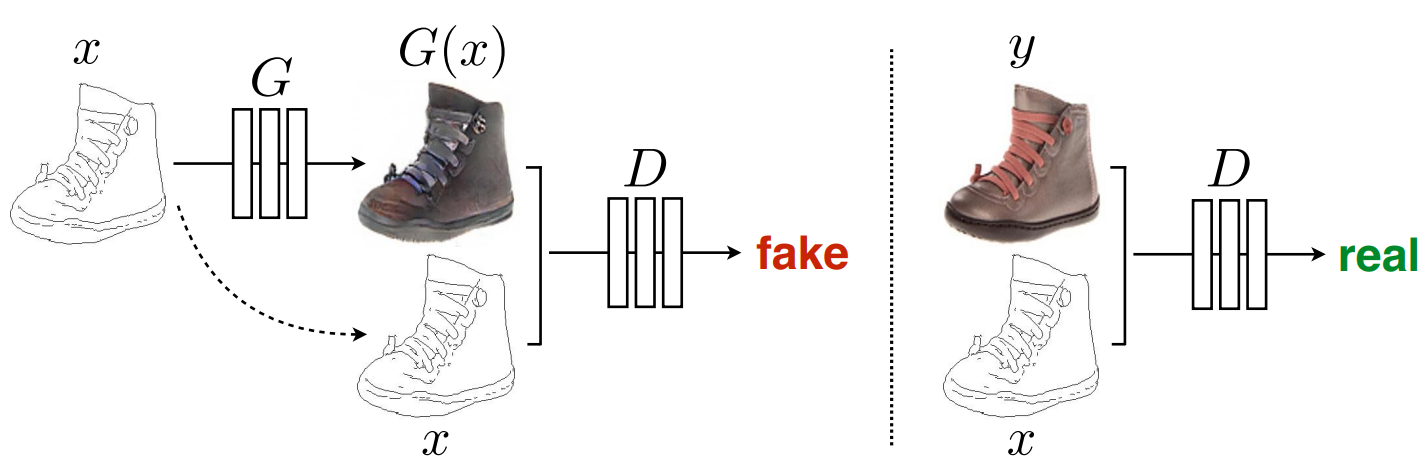
Pix2Pix: addestramento del discriminatore1
Discriminatore Pix2Pix: PatchGAN
Il discriminatore utilizzato nel modello Pix2Pix, non è un semplice discriminatore con una uscita per indicare la probabilità di verosimiglianza dell'output nel suo complesso, bensì un discriminatore PatchGAN con un output matriciale nella quale è riportata la probabilità di verosimiglianza di ogni determinata zona dell'output, in modo da favorire una rispondenza equilibrata del modello su tutte le aree dell'immagine. Chiaramente le corrispondenti label vero e falso di confronto saranno non scalari ma matrici riempite rispettivamente da 1 e 0,
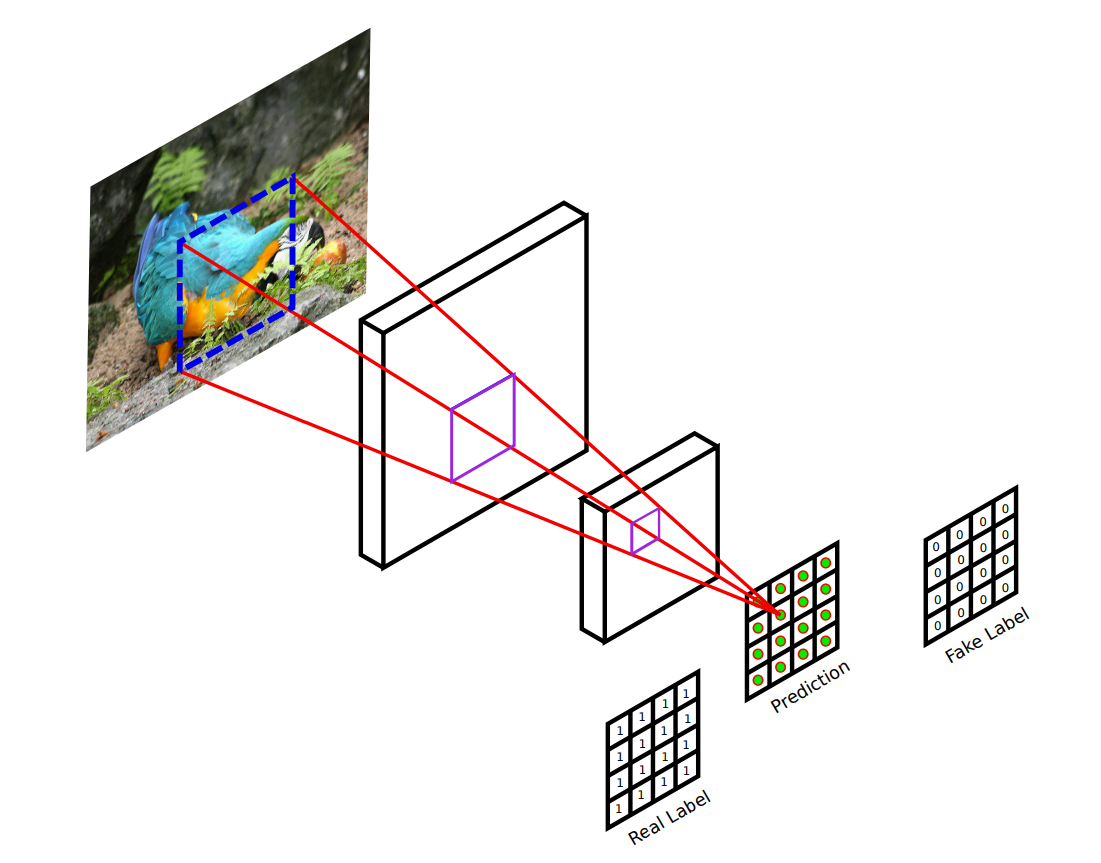
Discriminatore PatchGAN2
Generatore Pix2Pix: U-Net
L'architettura U-Net è utilizzata solitamente per compiti discriminativi di classificazione e segmentazione, dove c'è da attribuire una classe ad ogni punto dell'immagine. In questo caso la rete viene invece utilizzata come vero e proprio generatore per costruire un output verosimile.
La struttura di U-Net, in considerazione delle dimensioni analoghe di input e output, è di tipo encoder-decoder, nella quale i livelli successivi di encoding sono anche concatenati ai corrispondenti livelli di decoding attraverso delle skip-connection che agevolano sia il passaggio di informazione di dettaglio/specifica altrimenti persa nel processo di encoding, sia il flusso dei gradienti nella retropropagazione limitando il fenomeno della scomparsa del gradiente.
In alcuni blocchi del decoder possono essere inseriti dei layer di dropout che hanno la funzione, oltre che di regolarizzazione, di introdurre del rumore nella rete, (labilmente) correlato alla capacità della rete di variare l'output.
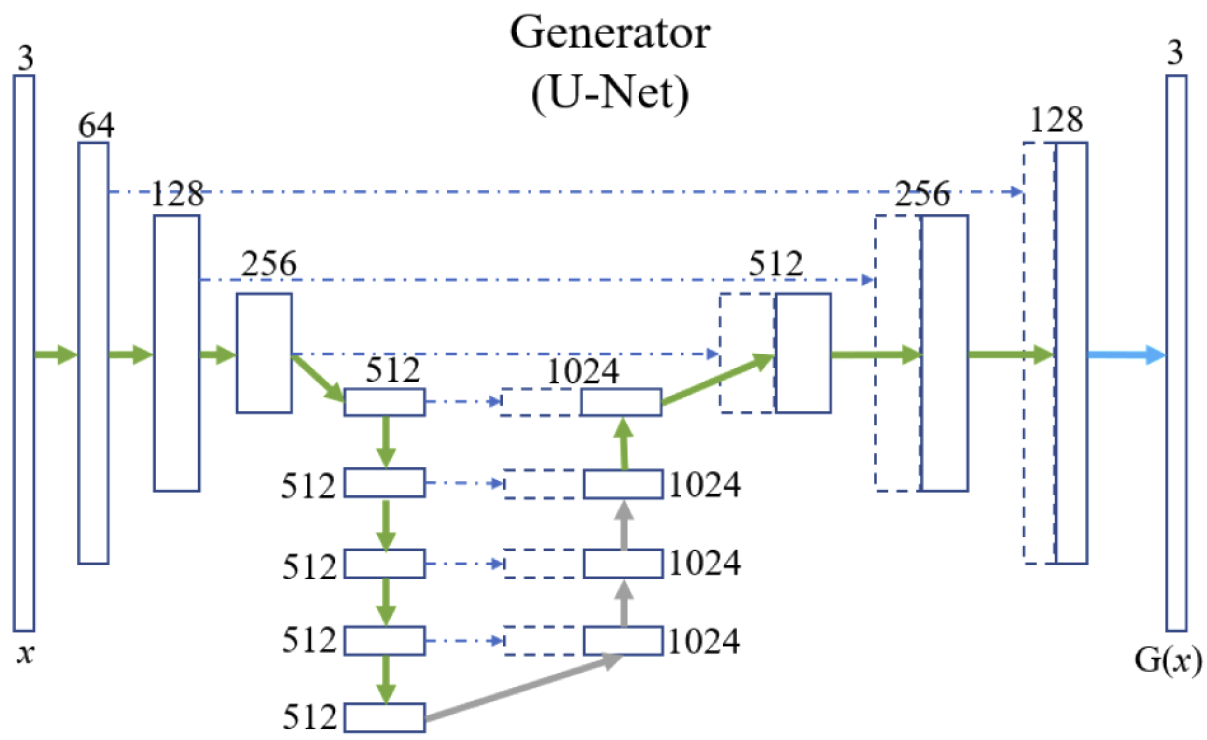
Pix2Pix U-Net Generator3
Generatore Pix2Pix: funzione di costo
La funzione di costo del modello, sulla quale ottimizzare i parametri del generatore e del discriminatore, sarà la consueta funzione BCE di costo base delle GAN condizionate \(\mathcal L(G,D)=\Bbb E_{x,y} [\log D(x,y)] + \Bbb E_{x,z}[\log(1-D(x,G(x,z))]\) che mira ad addestrare un generatore in grado di "ingannare il discriminatore", alla quale aggiungeremo un termine \(\mathcal L_{L1}=\Bbb E_{x,y,z} \lVert y-G(x,z) \rVert_1\) per incoraggiare il generatore a produrre output il più possibile aderenti a quelli del dataset reale.
Come accennato sopra, in queste formulazioni il rumore \(z\) viene inserito attraverso dei layer di dropout sia in fase di training che di test. Pertanto l'obiettivo finale del modello sarà:
\(\displaystyle \underset{G}{\min} \underset{D}{\max} \mathcal L(G,D)+\lambda \mathcal L_{L1}(G)\)
____________________
1 Isola, P., Zhu, J. Y., Zhou, T., & Efros, A. A. (2017). Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1125-1134). https://arxiv.org/abs/1611.07004
2 Demir, U., & Unal, G. (2018). Patch-based image inpainting with generative adversarial networks. arXiv preprint arXiv:1803.07422. https://arxiv.org/abs/1803.07422
3 Wang, Chenxing & Fanzhou, Wang & Guan, Qingze. (2021). Single-shot fringe projection profilometry based on Deep Learning and Computer Graphics. Optics Express. 29. 10.1364/OE.418430. https://arxiv.org/abs/2101.00814
